
티스토리 뷰
[Samsung SDS Brightics] Pre-processing : 결측값 처리 (2)
hae._.won1 2020. 8. 2. 21:04
여러분, 안녕하세요~?
이번 포스팅에서는 Pre-processing의 세 번째 단계인 결측값 처리 (2) 과정을 이어서 실습 해보려고 합니다 !
지난 포스팅에서 데이터 전처리 과정이 필요한 이유 중 하나인 결측값 ( Missing Value ) 에 대해서 알아보면서,
결측값의 첫 번째 유형 ! 문자형 결측값 처리 실습을 진행 해보았는데요 ~
이번 포스팅에서는 두 번째 유형 ! 숫자형 결측값 처리를 알아보려고 합니다 !
지난 시간과 이번 시간 두 시간에 걸쳐서 학습하니만큼 전처리 과정에서 결측값 처리는 ★ 매우 중요 ★ 하기 때문에,
아직 지난 포스팅을 보지 못하고 오신 분들은 지난 포스팅부터 먼저 ! 학습하고, 다음으로 ! 이번 포스팅을 이어서 학습하는 것을 추천드립니다 :)
https://haewon-world.tistory.com/14
[Samsung SDS Brightics] Pre-processing : 결측값 처리 (1)
여러분, 안녕하세요~? 이번 포스팅에서는 Pre-processing의 세 번째 단계인 결측값 처리 (1) 과정을 실습 해보려고 합니다 ! 데이터 전처리 과정에서 가장 중요하게 다뤄야 하는 값 중 하나인 결측값 (
haewon-world.tistory.com
자 ! 그러면 이제 본격적으로 [Pre-processing] Missing Value Processing (2) Number 실습을 시작해보도록 할까요~?
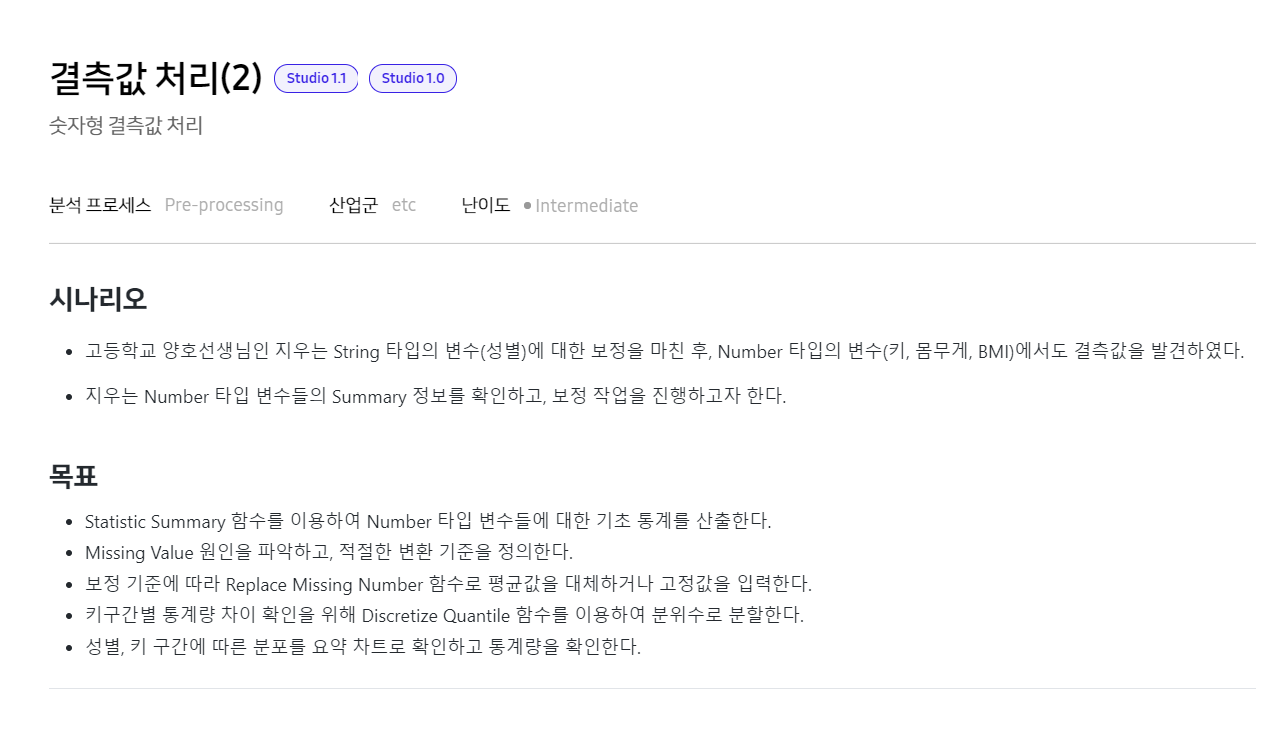
■ Data Preparation
→ 숫자형 ( Number ) 결측값 : height 변수 - 키
weight 변수 - 몸무게
bmi 변수 - 체질량지수
[ 09_2_py_bmi.csv ]
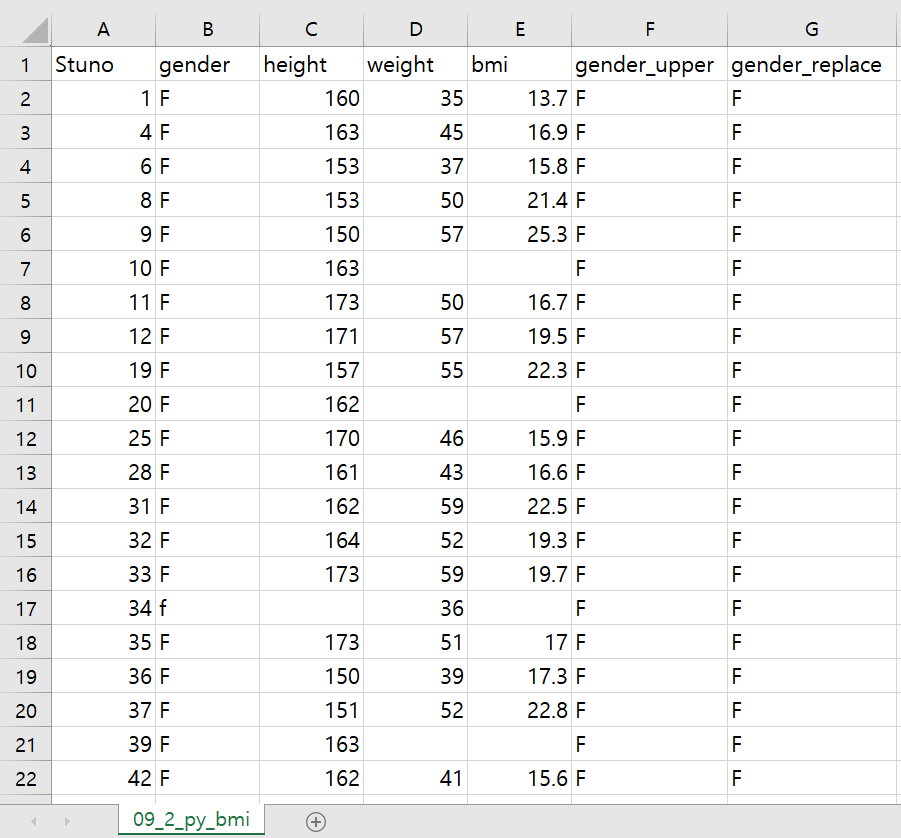
■ Data Load ( Load 함수 )
0. Load 함수의 경로를 업로드한 데이터인 09_2_py_bmi 로 지정하여 실행합니다.
→ height 변수인 키 정보, weight 변수인 몸무게 정보, bmi 변수인 체질량지수 정보의 결측값 처리 필요 !
( Double 타입의 변수들에 null이라는 Missing Value 포함 )
※ 09_2_py_bmi 데이터를 다운로드 받아도 되지만, 지난 포스팅에서 실습한 '결측값 처리 (1) - 문자형 결측값 처리'의 수행 최종 결과 데이터 이용시에는 다운로드 받지 않고 이어서 사용 가능 !
■ Pre-processing 1 ( Statistic Summary 함수 )
▶▷ Statistic Summary 함수를 이용하여 숫자 타입 변수들에 대한 기초 통계 산출하기 + Missing Value 원인을 파악하고, 적절한 변환 기준 정의하기 ◁◀
1. 새로운 함수를 생성하기 위해서 Select Function 팝업창이 뜨면, Statistic Summary 함수 버튼을 클릭하고
Load 함수로부터 Input 값을 받기 위해서 연결합니다.
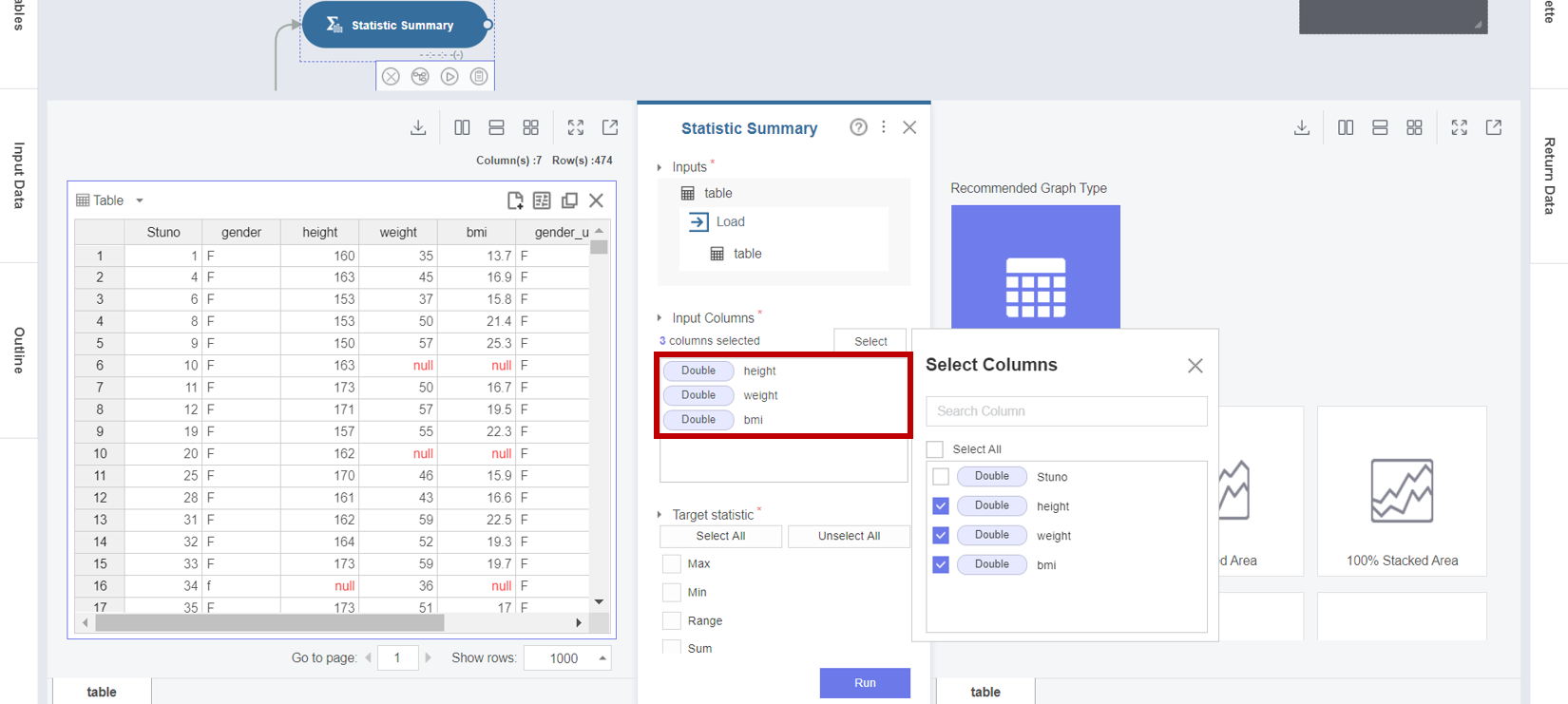
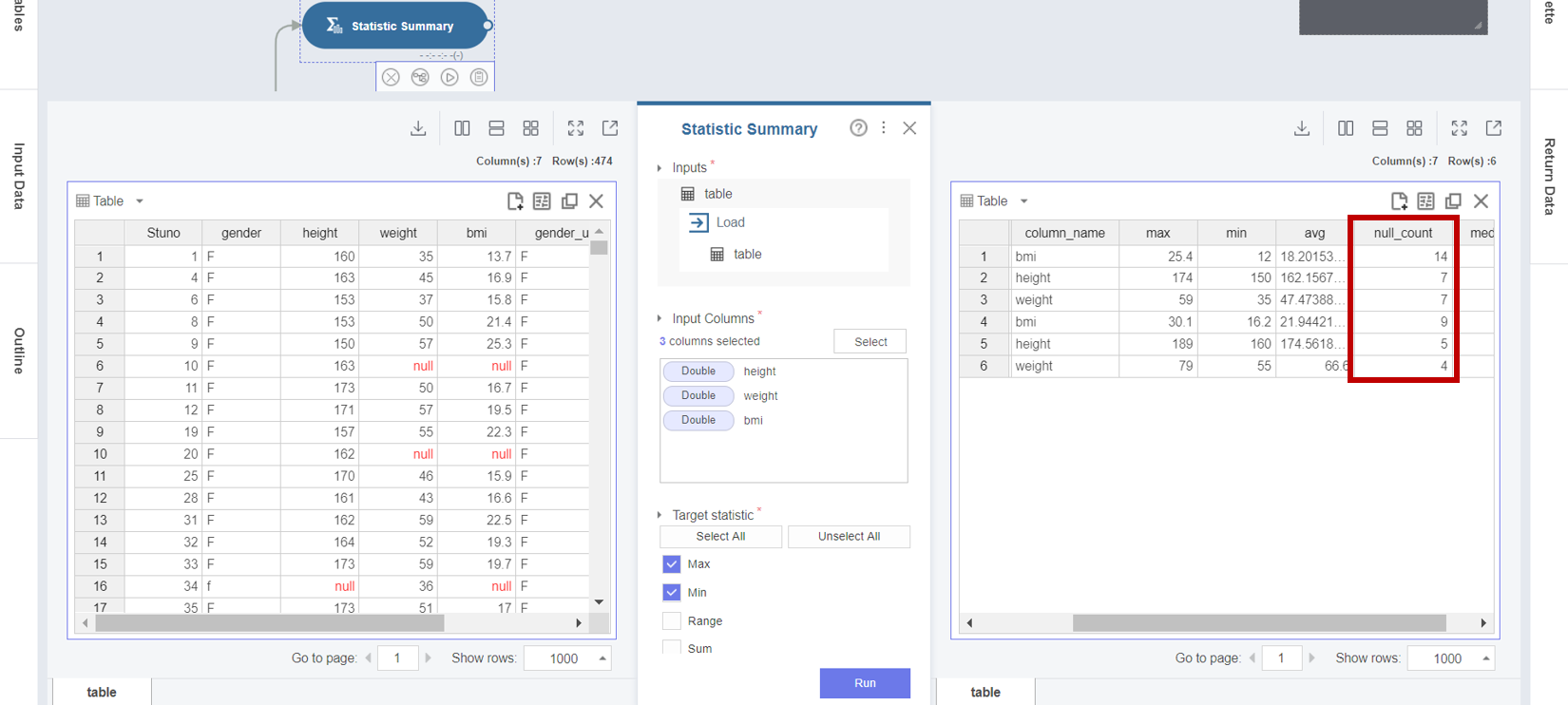
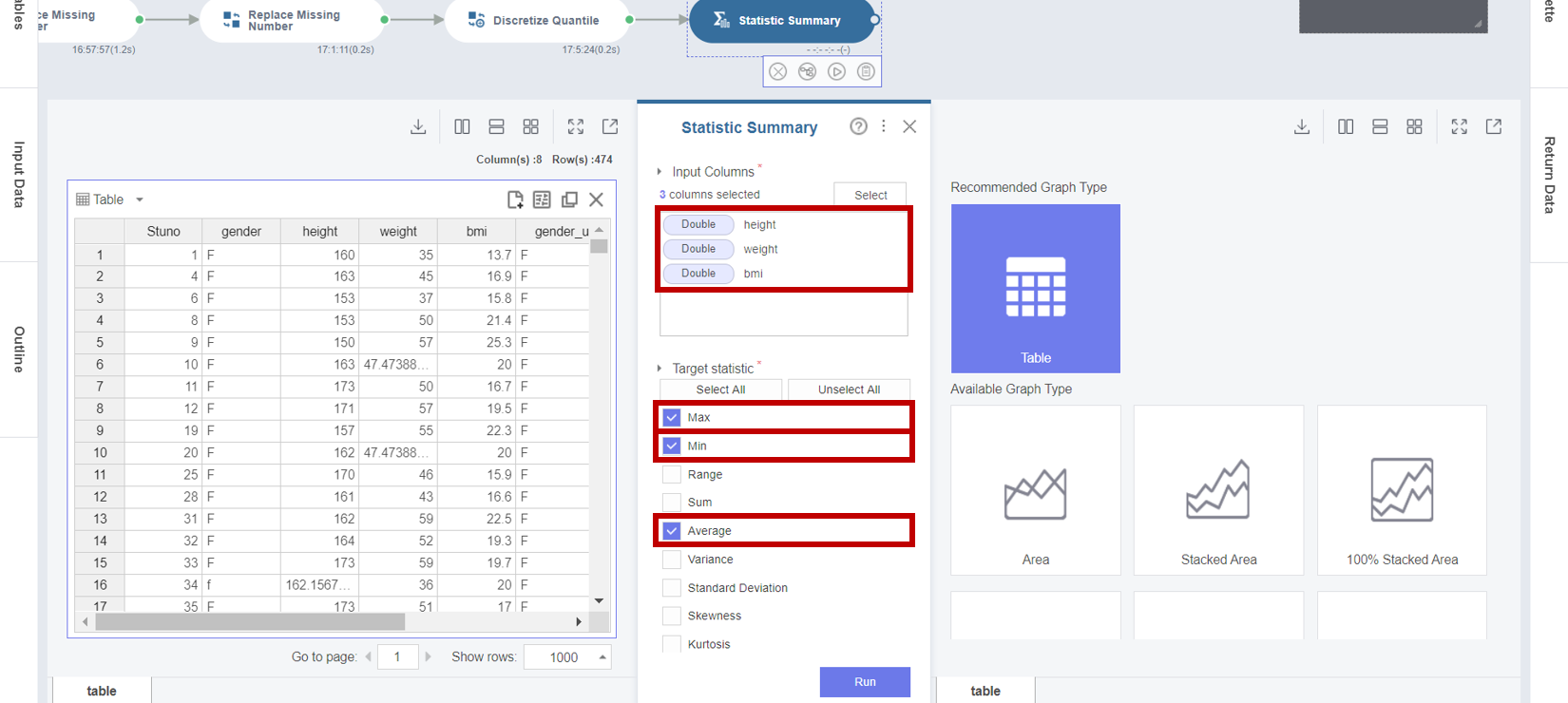
2. Double 타입의 결측값과 기초 통계량을 확인하기 위해서 Statistic Summary 함수의 Properties Panel에서
- Input Columns : height (키) 변수, weight (몸무게) 변수, bmi (체질량지수) 변수
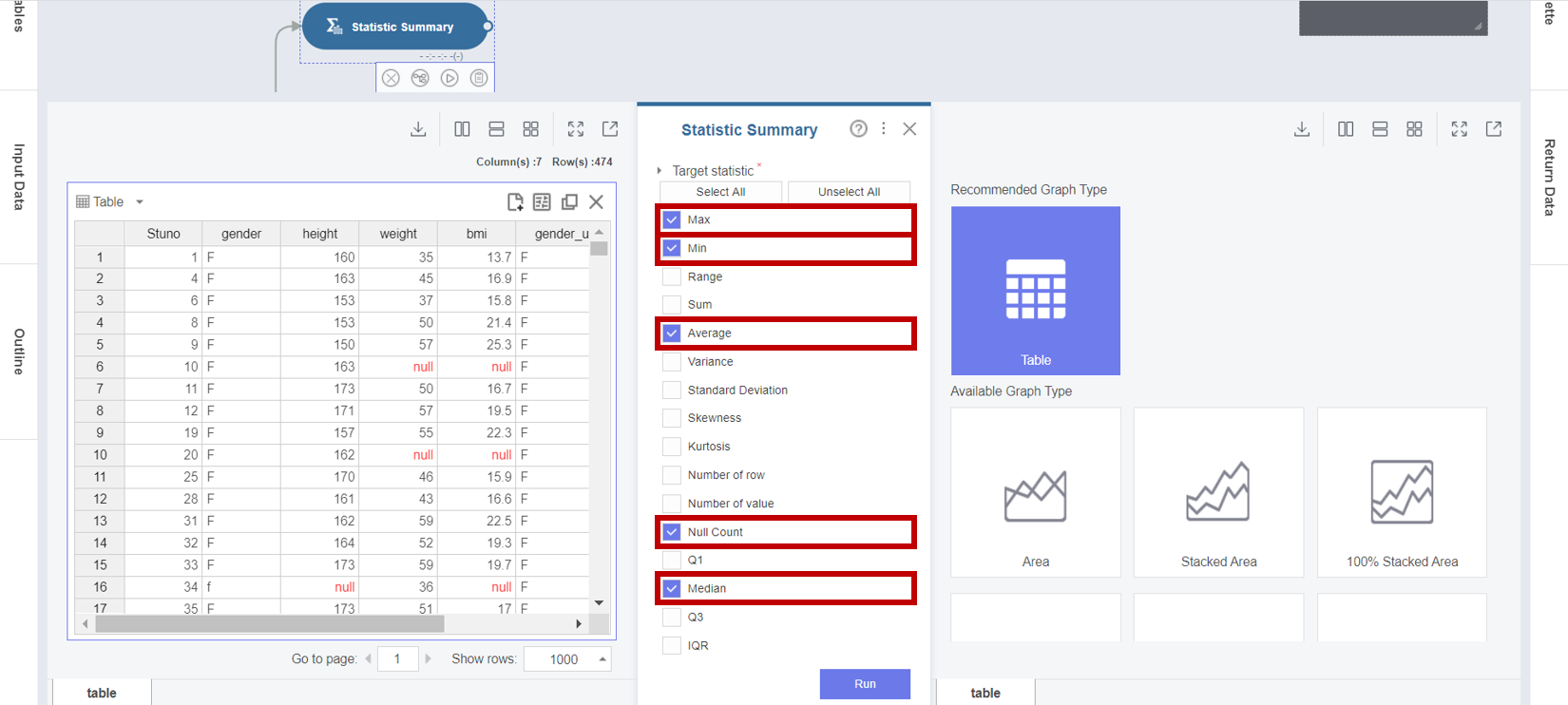
- Target Statistic : Max, Min, Average, Null Count, Median
- Group By : gender_replace (성별)
선택을 마친 후 Run 버튼을 클릭합니다.
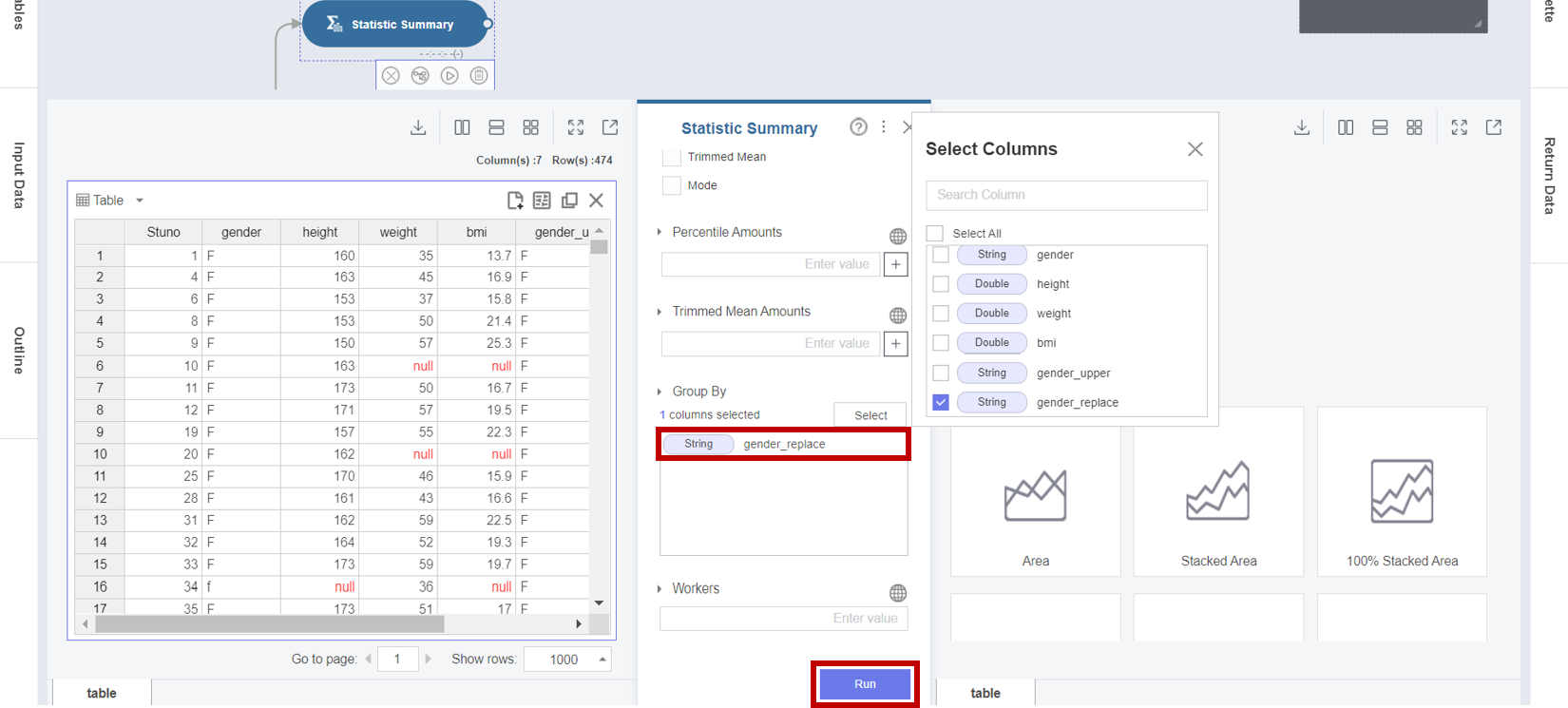
3. Statistic Summary 함수의 결과 테이블에서 null 데이터의 Count를 확인할 수 있으며 기초 통계량은 null 값인 데이터를 제외하고 계산됩니다.
■ Pre-processing 2 ( Replace Missing Number 함수 )
▶▷ Replace Missing Number 함수로 보정 기준에 따라 평균값을 대체하기 ◁◀
1. 새로운 함수를 생성하기 위해서 Select Function 팝업창이 뜨면, Replace Missing Number 함수를 클릭합니다.
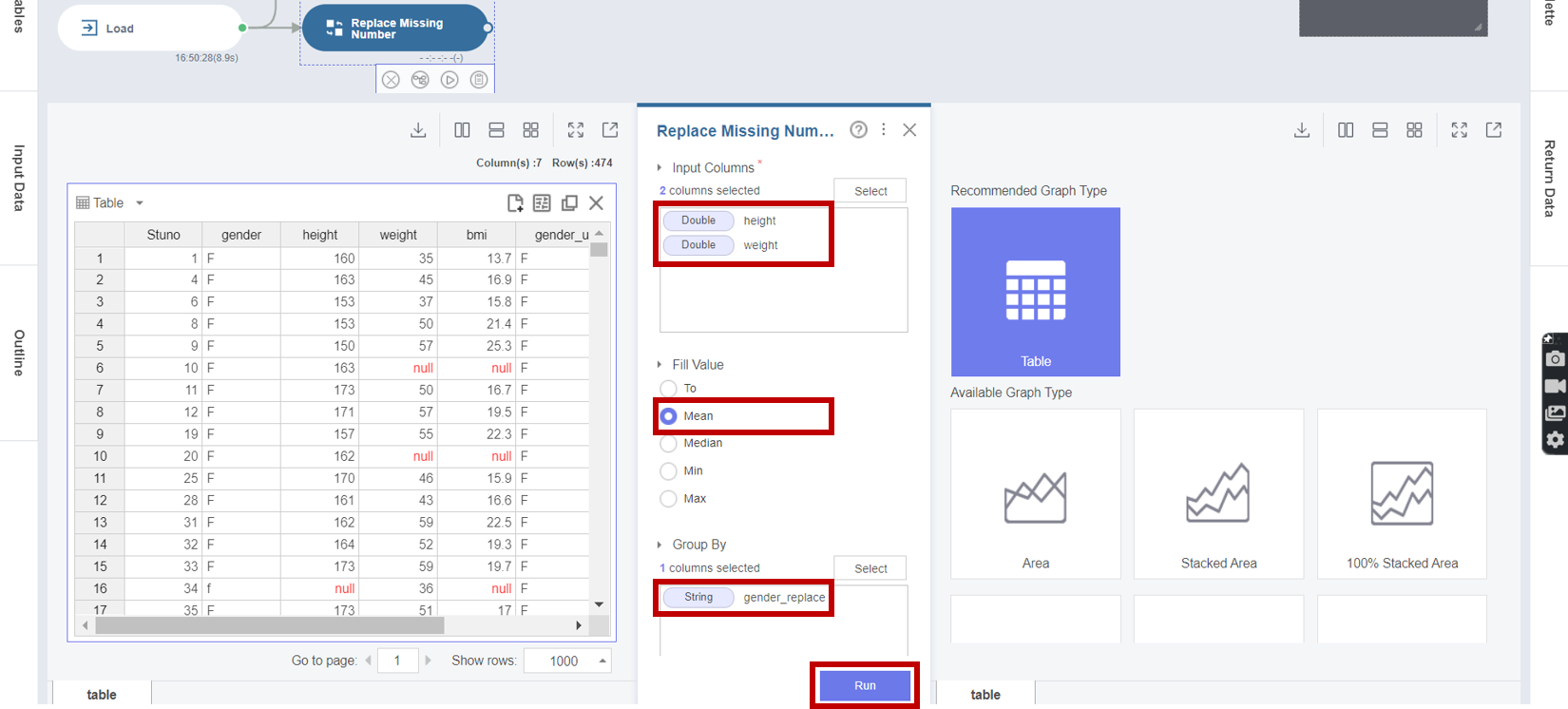
2. Replace Missing Number 함수로 Double 변수들의 Missing Value (null) 를 평균값 (mean) 으로 대체하기 위해서
Input Columns로 height와 weight를 선택하고, Fill Value로 Mean을 선택하며, Group By로 gender_replace (보정한 성별 구분) 를 선택한 후 Run 버튼을 클릭합니다.
※ 실제 입력값이 Missing인 height과 weight에 대해서 평균값으로 대체 !
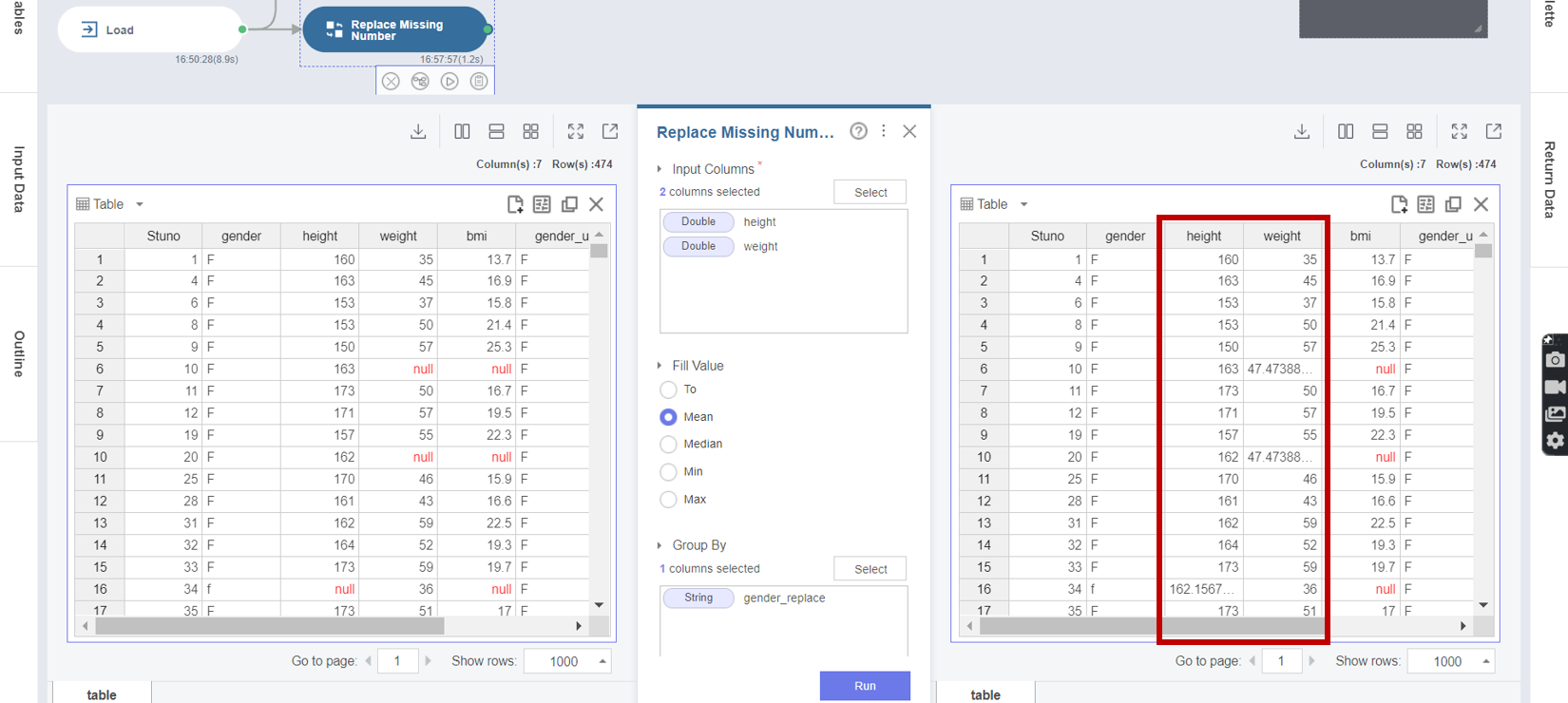
3. Replace Missing Number 함수의 실행 결과 height 변수와 weight 변수의 null 값이 남녀별 평균값으로 변환된 것을 확인할 수 있습니다.
▶▷ Replace Missing Number 함수로 보정 기준에 따라 고정값을 입력하기 ◁◀
4. 동일한 함수를 생성하기 위해서 Select Function 팝업창이 뜨면, Replace Missing Number 함수를 클릭합니다.
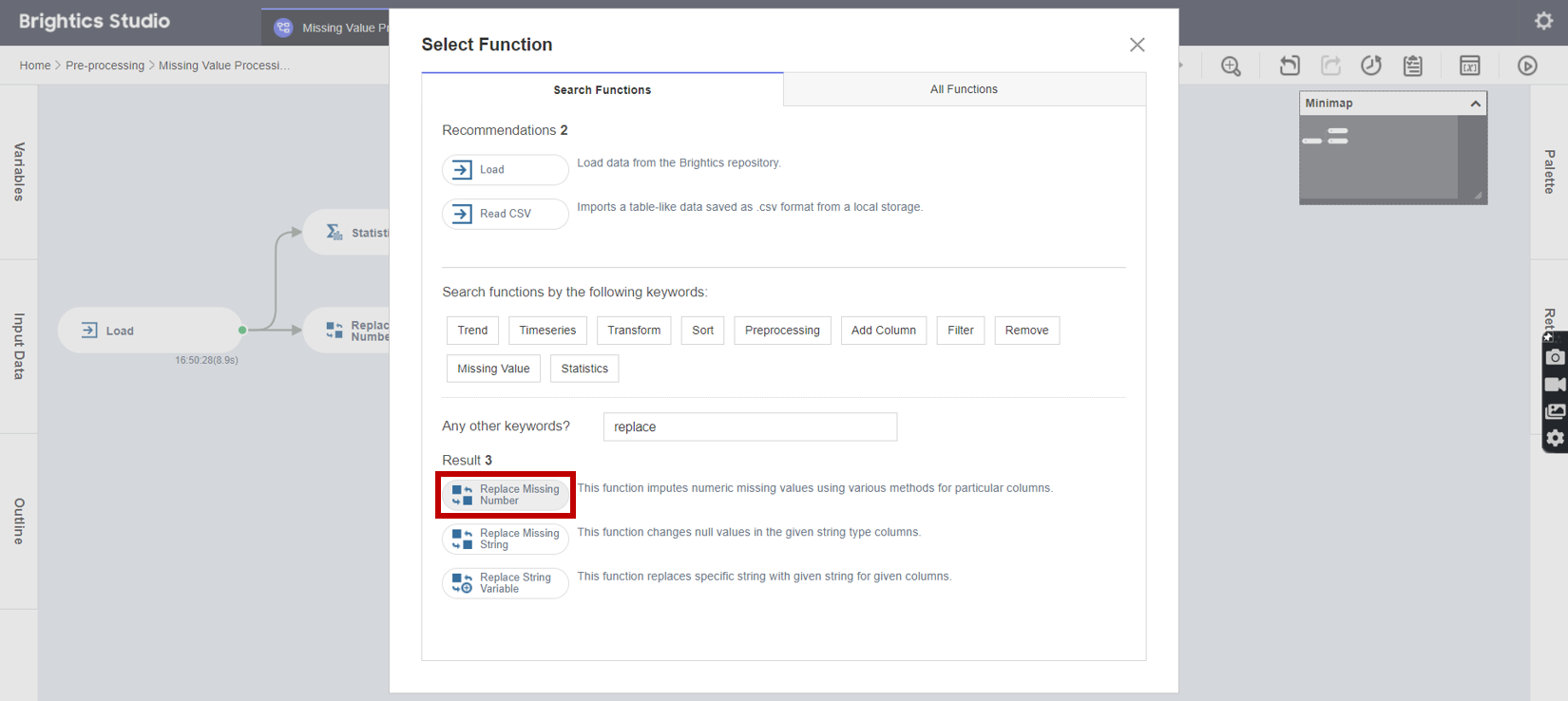
5. Replace Missing Number 함수로 Double 변수들의 Missing Value (null) 를 특정 입력값 (20) 으로 대체하기 위해서
Input Columns로 bmi를 선택하고, Fill Value로 To를 선택하며, Fill Holes With으로 20을 입력한 후 Run 버튼을 클릭합니다.
※ bmi는 Input 변수인 height과 weight 중 하나의 값만 없어도 계산이 되지 않고 NaN 값을 가지기 때문에
보정된 Input 변수의 평균값을 재사용한 계산보다는 bmi 표준수준에 해당하는 고정값 20 부여하기 추천 !
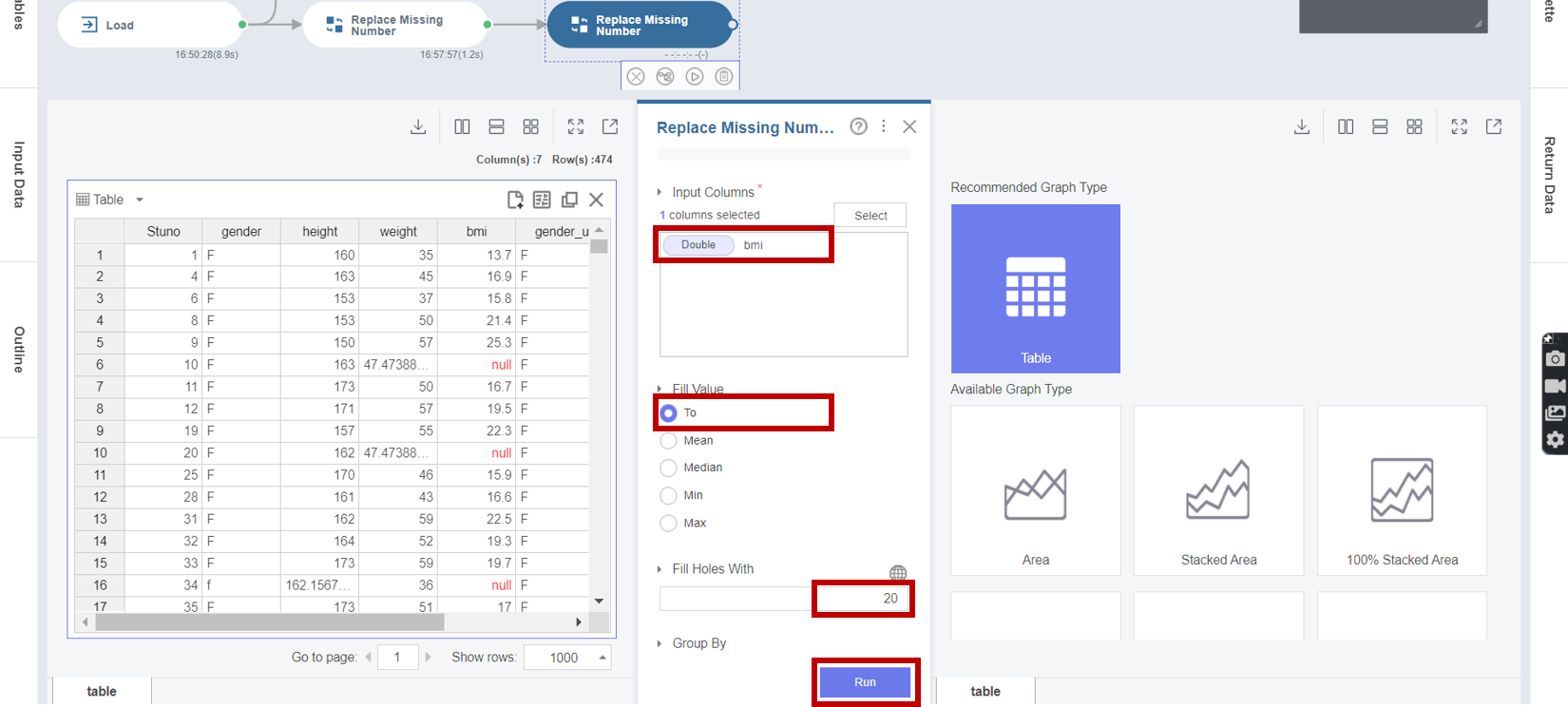
6. Replace Missing Number 함수의 실행 결과 bmi 변수의 null 값이 20으로 변환된 것을 확인할 수 있습니다.
■ Pre-processing 3 ( Discretize Quantile 함수 )
▶▷ Discretize Quantile 함수로 키구간별 통계량 차이 확인을 위해 분위수로 분할하기 ◁◀
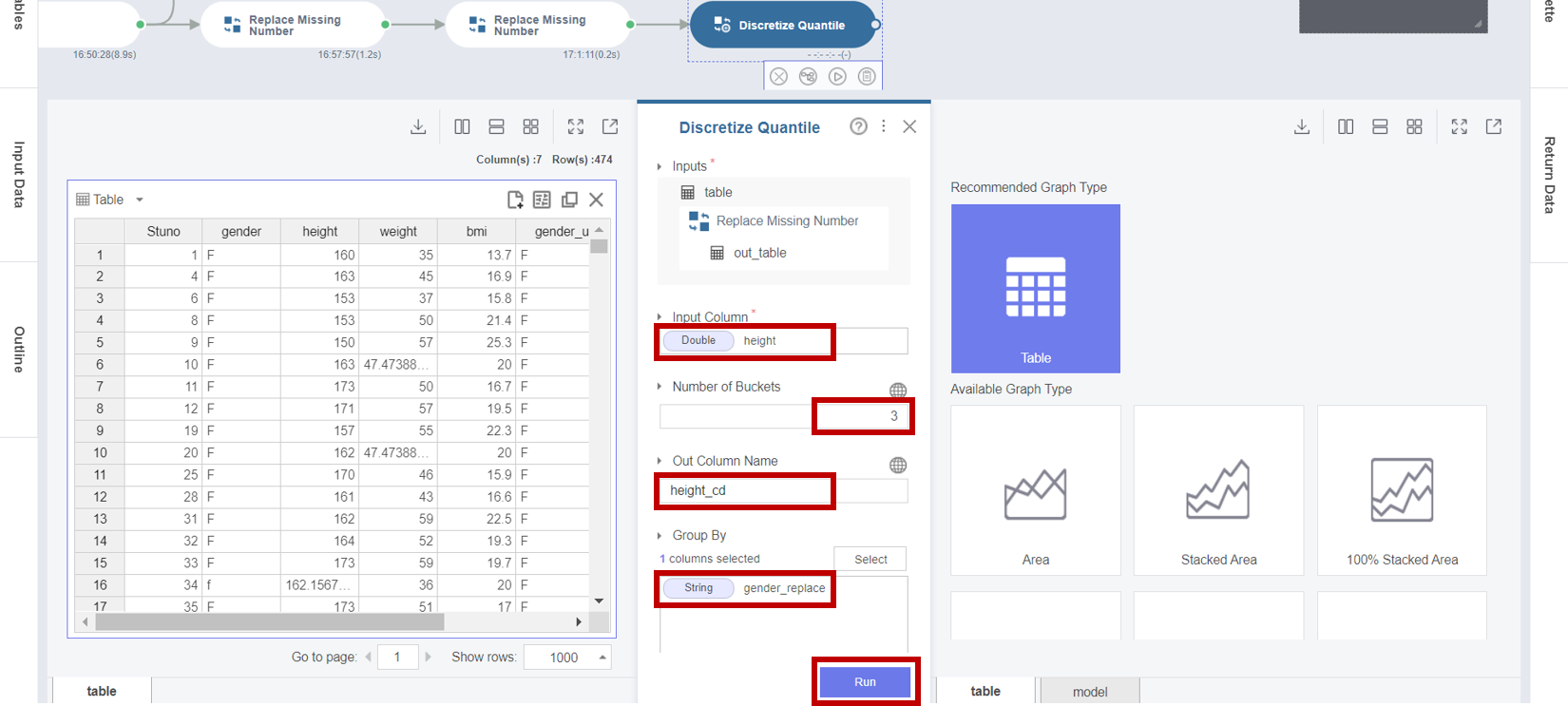
1. 새로운 함수를 생성하기 위해서 Select Function 팝업창이 뜨면, Discretize Quantile 함수 버튼을 클릭합니다.
2. Discretize Quantile 함수로 Double 변수를 입력값의 분위수로 구간을 분할하기 위해서
Input Columns로 height를 선택하고, Number of Buskets로 3을 입력하며, Out Column Name으로 height_cd를 입력하고, Group By로 gender_replace를 선택한 후 Run 버튼을 클릭합니다.
※ 보정된 지표에 대한 성별간 차이 비교를 위해 남녀별 height 변수를 기준으로 3개의 분위수로 분할 !
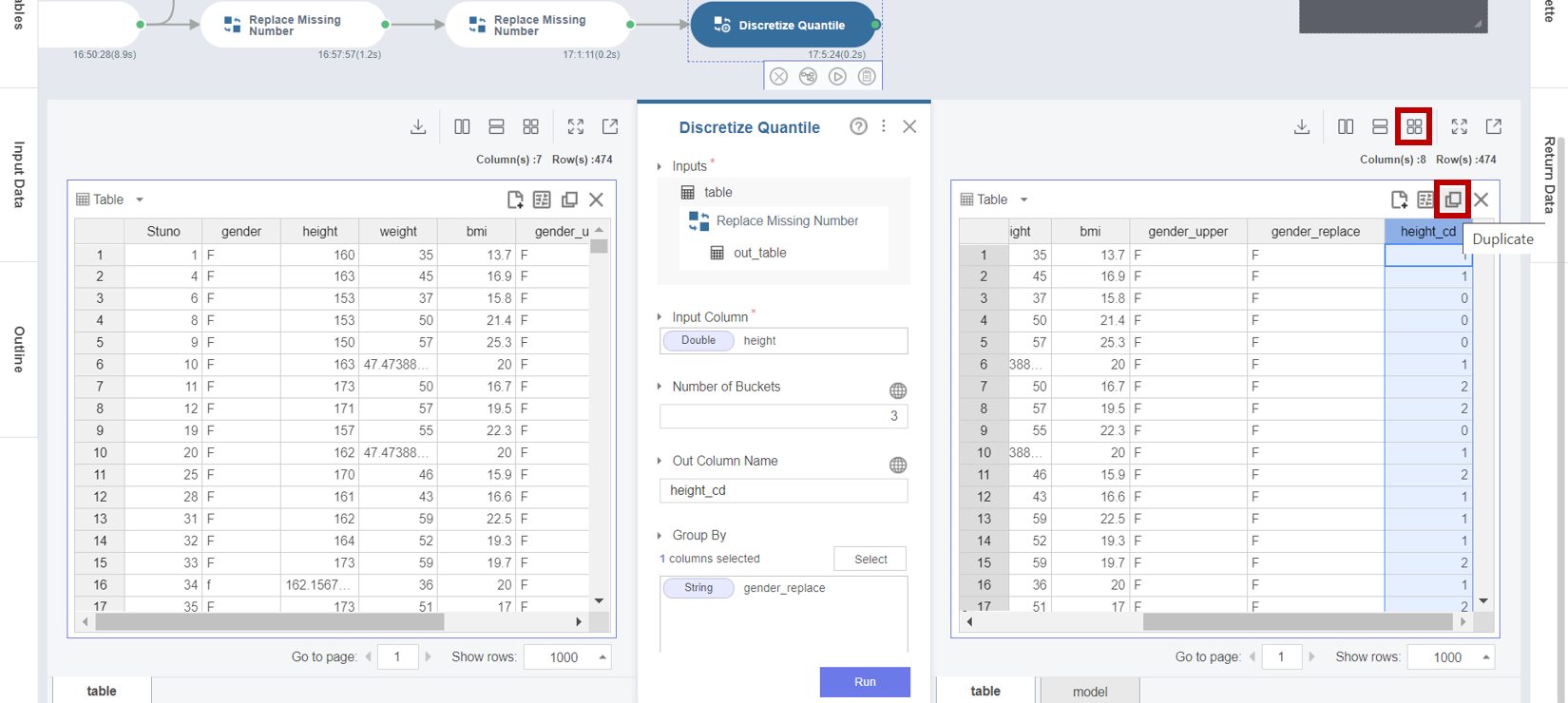
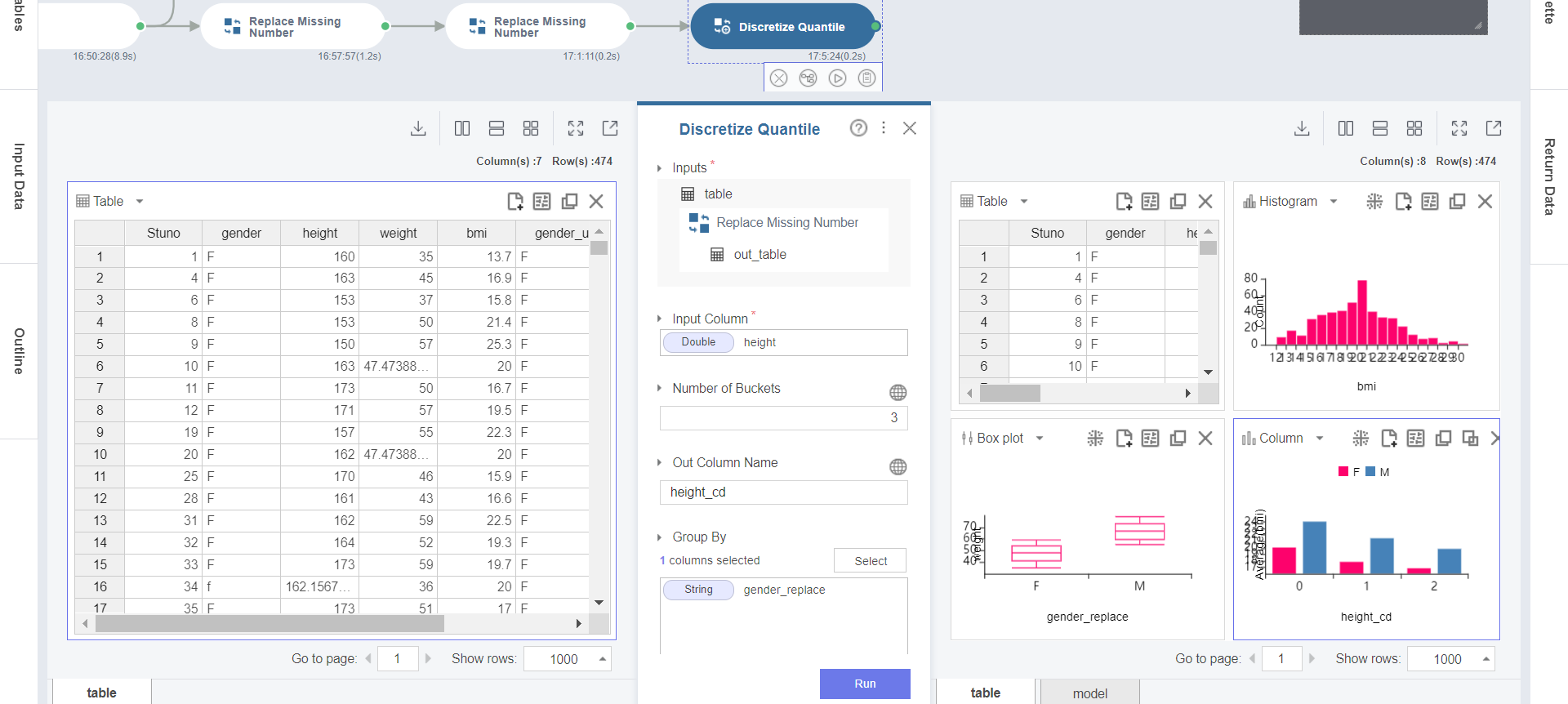
3. Discretize Quantile 함수의 실행 결과 height_cd가 3개의 분위수 ( 0, 1, 2 ) 로 나눠진 것을 확인할 수 있고,
Duplicate -> Evenly -> Chart Settings 의 조정을 통해 Table / Histogram / Box plot / Column 등의 다양한 차트로
전체, 성별, 키 구간에 대한 분포를 확인할 수 있습니다.
■ Pre-processing 4 ( String Summary 함수 )
▶▷ Statistic Summary 함수를 이용하여 성별, 키 구간에 따른 분포를 요약 차트와 통계량 확인하기 ◁◀
1. 새로운 함수를 생성하기 위해서 Select Function 팝업창이 뜨면, Statistic Summary 함수 버튼을 클릭합니다.
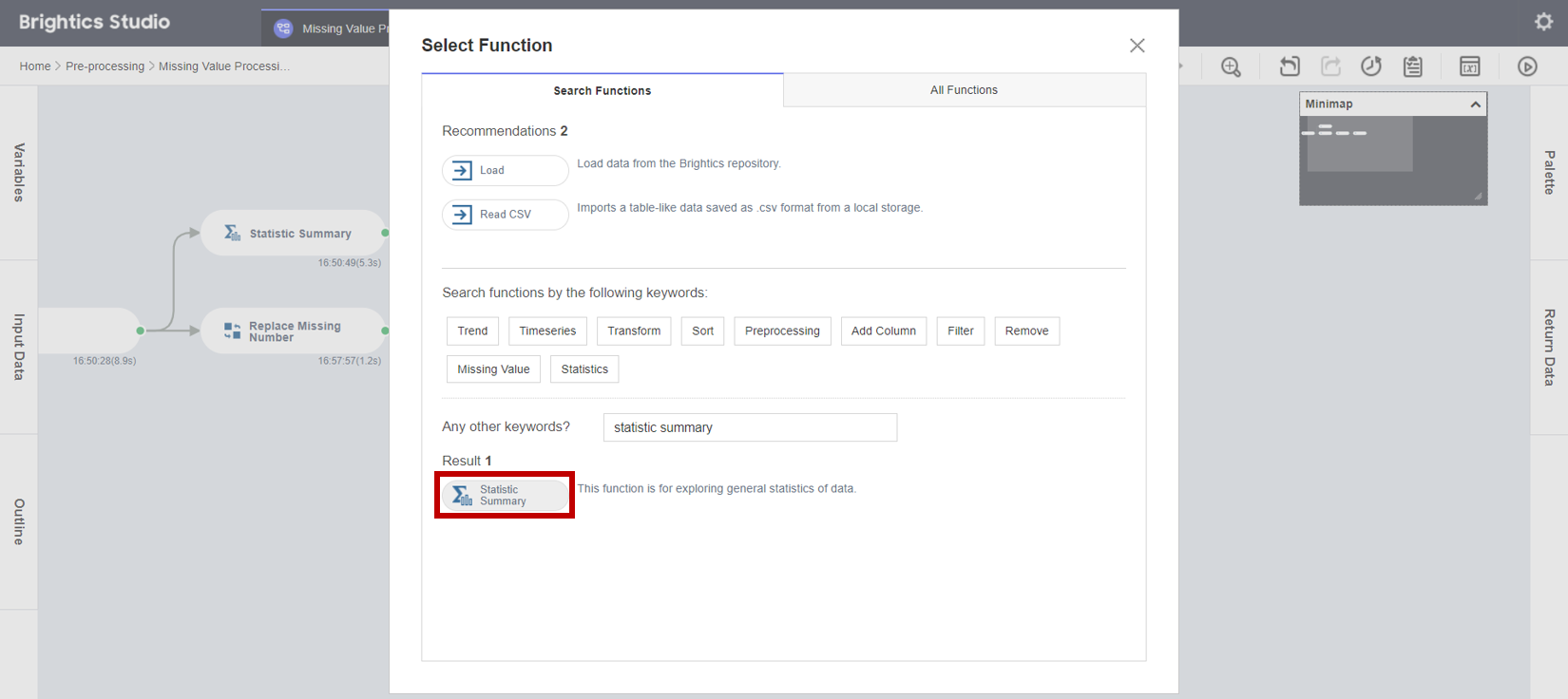
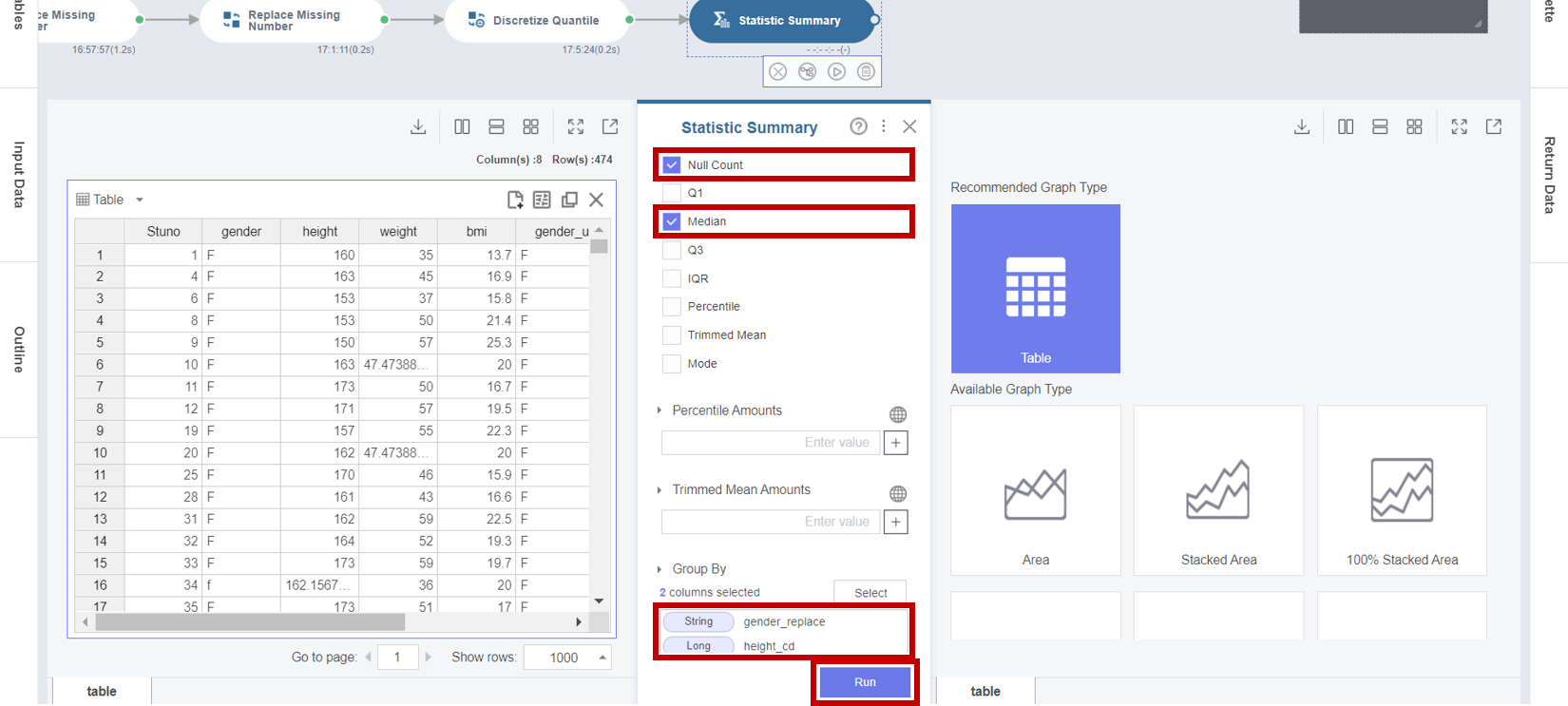
2. 보정된 Double 타입의 결측값과 기초 통계량을 확인하기 위해서 Statistic Summary 함수의 Properties Panel에서
- Input Columns : height (키) 변수, weight (몸무게) 변수, bmi (체질량지수) 변수
- Target Statistic : Max, Min, Average, Null Count, Median
- Group By : gender_replace (성별), height_cd (키 구간)
선택을 마친 후 Run 버튼을 클릭합니다.
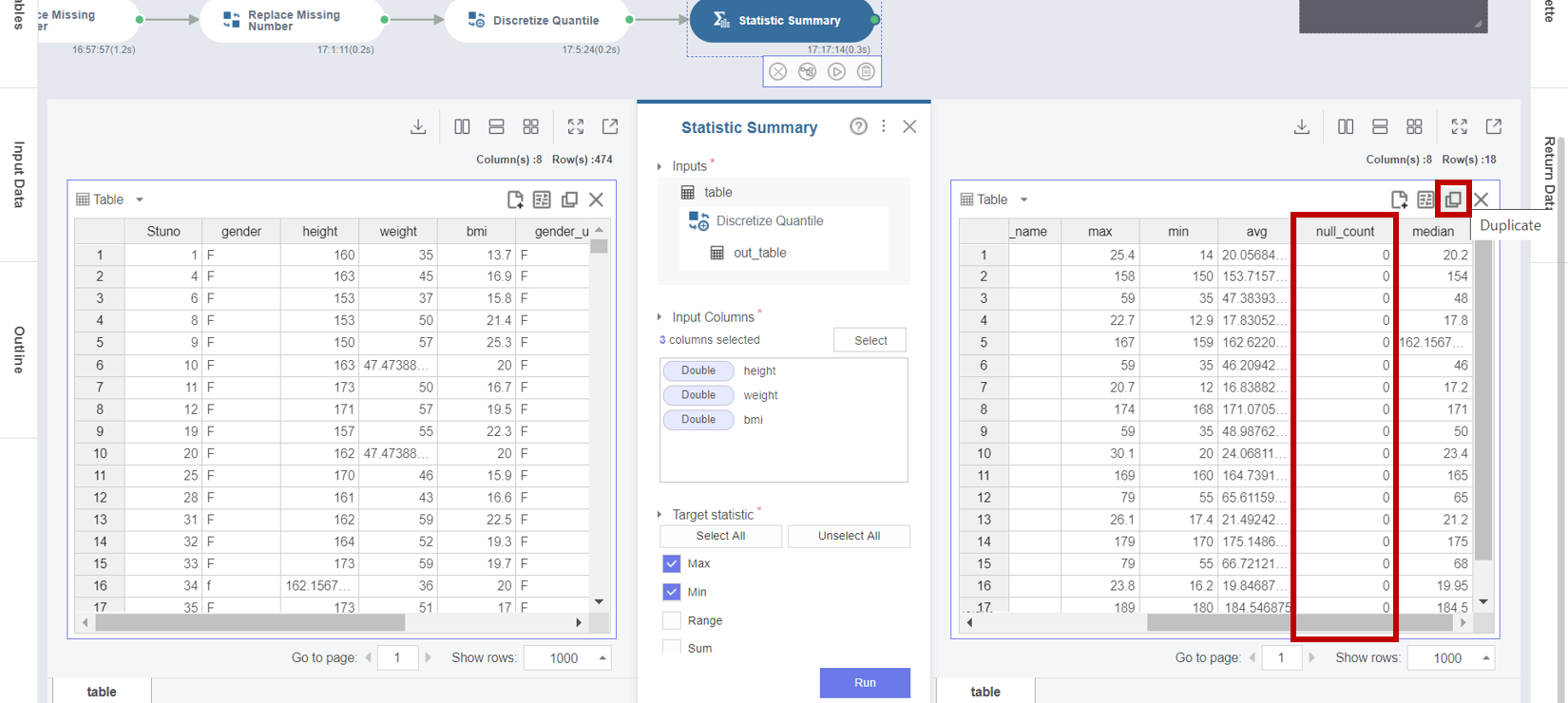
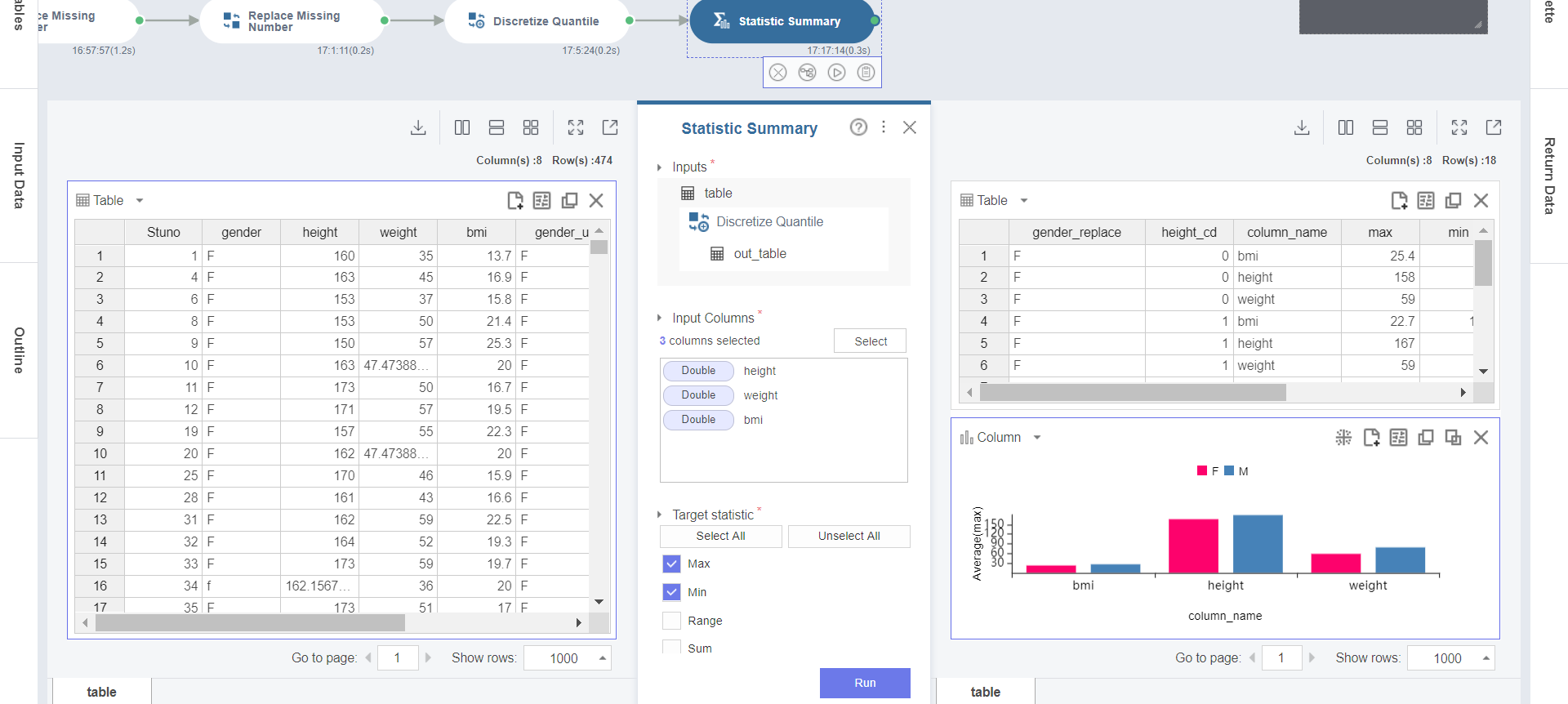
3. Statistic Summary 함수의 결과 테이블에서 height (키), weight (몸무게), bmi (체질량지수) 의 Missing Value가 모두 보정 되어 Null Count가 모두 0으로 나타나고 있다는 것을 확인할 수 있으며 기초 통계량도 정상적으로 계산됩니다.
분포결과를 테이블과 차트 두 가지로 확인하기 위해서 Duplicate 버튼을 클릭합니다.
4. Chart Settings에서 Chart Type을 Columns로 설정하고,
X-axis를 column_name, Y-axis를 Average(max), Color By를 gender_replace로 설정합니다.
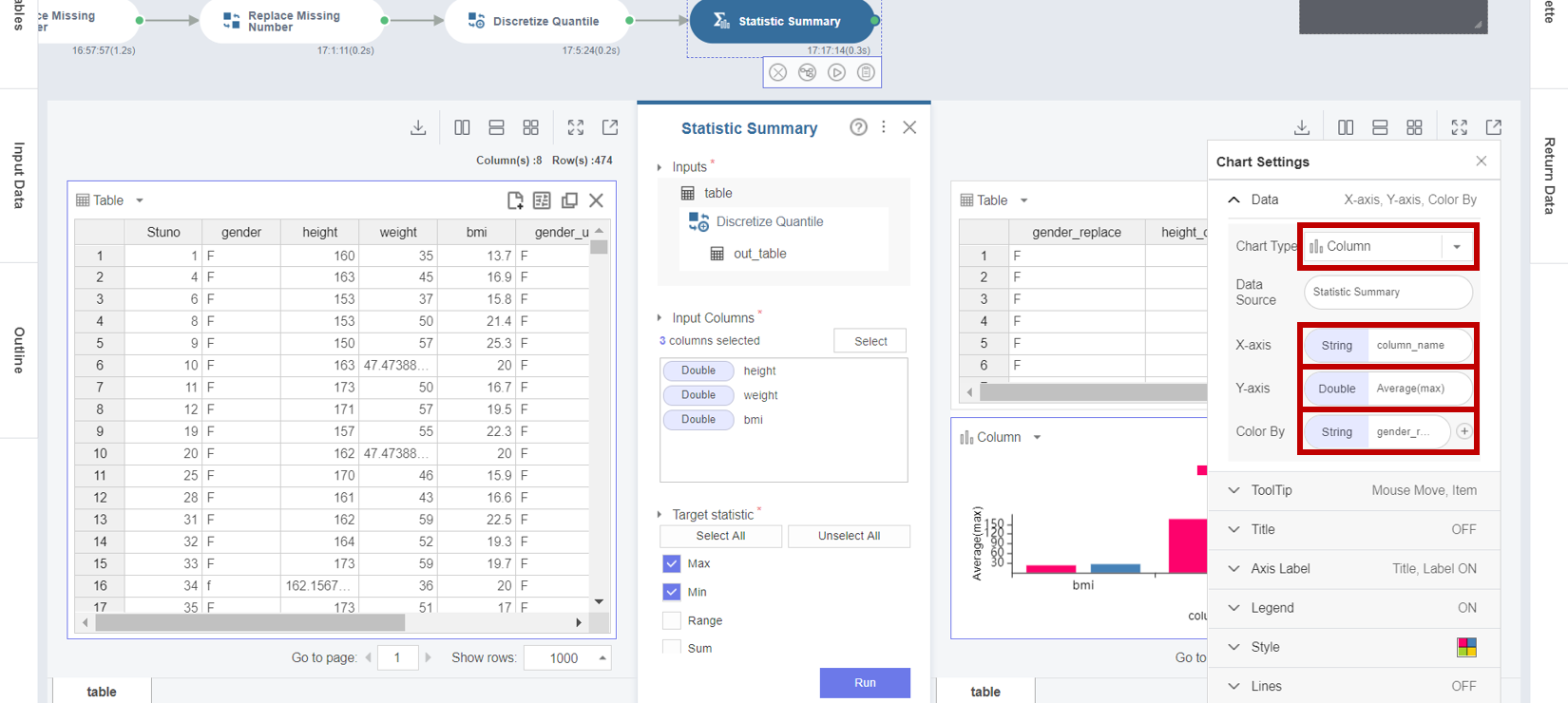
5. Statistic Summary 함수의 결과 차트에서 gender_replace로 bmi, height, weight에 대한 Average 값을 비교해보면 전반적으로 남학생이 조금 높은 값을 알 수 있습니다.
지금까지 ~ 전처리 - 결측값 처리(2) 숫자형 결측값 처리 튜토리얼 실습이었습니다 !
※ Tutorial → [ Pre-processing ] Missing Value Processing (2)
감사합니다 :)
https://www.brightics.ai/kr/docs/ai/s1.0/tutorials/09_2_py_Missing_Number_Imputation?type=insight
Brightics Studio
www.brightics.ai
'Samsung SDS Brightics' 카테고리의 다른 글
| [Samsung SDS Brightics] Pre-processing : 이상값 탐지 및 제거 (2) (0) | 2020.08.04 |
|---|---|
| [Samsung SDS Brightics] Pre-processing : 이상값 탐지 및 제거 (1) (0) | 2020.08.03 |
| [Samsung SDS Brightics] Pre-processing : 결측값 처리 (1) (0) | 2020.08.01 |
| [Samsung SDS Brightics] Pre-processing : 데이터 샘플링 (0) | 2020.07.28 |
| [Samsung SDS Brightics] Pre-processing : 데이터 업로드 & 데이터 결합 (0) | 2020.07.25 |
- Total
- Today
- Yesterday
- Missing Value
- Brightics Studio 실습
- 전처리
- 브라이틱스
- 데이터 전처리
- Brightics 개인미션
- 전파누리
- ANOVA
- Brightics 홍보 UCC
- 데이터참쉽조
- Brightics 서포터즈
- 결측값 처리
- 삼성 SDS
- Brightics Studio
- Public Wifi
- 데이터전처리
- ANOVA 검정
- Brightics 분석 프로젝트
- 이상값 탐지 및 제거
- Brightics Tutorial
- mtcars
- 한국공항공사
- eda
- data analysis
- Brightics 팀미션
- Brightics AI
- 삼성 SDS 데이터 분석 프로젝트
- Brightics 팀 분석 프로젝트
- Wifi Free
- 브라이틱스 스튜디오
- 결측치 처리
- Brightics vs R
- Outlier Detection and Removal
- 분석 프로젝트
- 브라이틱스 튜토리얼
- 삼성 SDS 데이터 분석
- 전처리 과정
- Brightics 개인 분석 프로젝트
- Pre-processing
- 이상값
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |