
티스토리 뷰
[Samsung SDS Brightics] Pre-processing : 이상값 탐지 및 제거 (1)
hae._.won1 2020. 8. 3. 02:25
여러분, 안녕하세요~?
이번 포스팅에서는 Pre-processing의 네 번째 단계인 이상값 탐지 및 제거 (1) 과정을 실습 해보려고 합니다 !
데이터 전처리 과정에서 결측값 ( Missing Value ) 처리와 더불어 가장 중요하게 다뤄야 하는 과정은 무엇일까요~?
바로, 이상값 ( Outlier ) 처리입니다 !
이상값 ( Outlier ) 이란, 정상 범주에서 크게 벗어난 이상한 값으로
논리적으로 존재할 수 없거나 극단적인 값을 의미합니다.
이러한 이상값은 분석 결과를 왜곡시키고 분석 모델의 성능 저해 문제를 발생시키기 때문에
데이터 분석 전 결측값과 함께 전처리 과정이 반드시 필요한데요 !
★ 주의사항 ★ 으로는 ! 결측값의 존재 여부를 쉽게 판단 할 수 있었던 것과 달리,
이상값의 존재 여부는 측정 기준에 따라서 판단 여부가 달라지는 어려움이 있다는 것입니다 !
따라서 이상값의 탐지 방법에 따라 이번 포스팅과 다음 포스팅 두 시간에 걸쳐서 알아보려고 합니다 :)
이번 포스팅에서는 Tukey 방법을 활용해보고, 다음 포스팅에서는 Local Outlier Factor 방법을 활용 해보겠습니다 !
이상값을 탐지하는 대표적인 방법 첫 번째 ! Tukey 방법이란,
1사분위수 ( Q1, 하위 25% 값 ) 와 3사분위수 ( Q3, 상위 25% 값 ) 사이의 거리 간격인
IQR ( Inter Quantile Range ) 에 특정 수 ( 주로 1.5 ) 를 곱해서 그 수를 벗어나는 값을 이상값으로 정의합니다.
다시 말해서, 1사분위수를 기준으로 IQR의 1.5배보다 작은 부분인 ( Q1 - IQR * 1.5 ) 이상 작은 값이나,
3사분위수를 기준으로 IQR의 1.5배보다 큰 부분인 ( Q3 + IQR * 1.5 ) 이상 큰 값을 이상값으로 표현합니다.
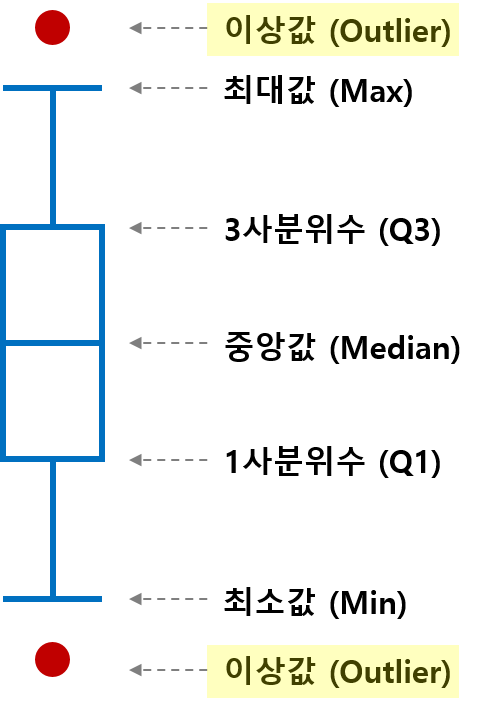
특히 Tukey 방법은 1사분위수와 3사분위수 사이의 거리 간격인 IQR을 이용하기 때문에
최소값, 1사분위수 (Q1, 하위 25%), 2사분위수 (Q2, 중앙값), 3사분위수 (Q3, 상위 25%), 최대값
5가지 수치를 한 번에 시각적으로 표현할 수 있는 Box Plot 차트와 함께 사용한다는 점도 꼭 ! 기억해주세요 ☆
자 ! 그러면 이제 본격적으로 [Pre-processing] Outlier Detection and Removal (1) Tukey 실습을 시작해보도록 할까요~?
■ Data Preparation
[ 11_py_outlier_detection.csv ]
■ Data Load ( Load 함수 )
▶▷ 데이터셋에 포함되어 있는 이상치를 Box Plot을 사용하여 시각적으로 탐색하여 확인하기 ◁◀
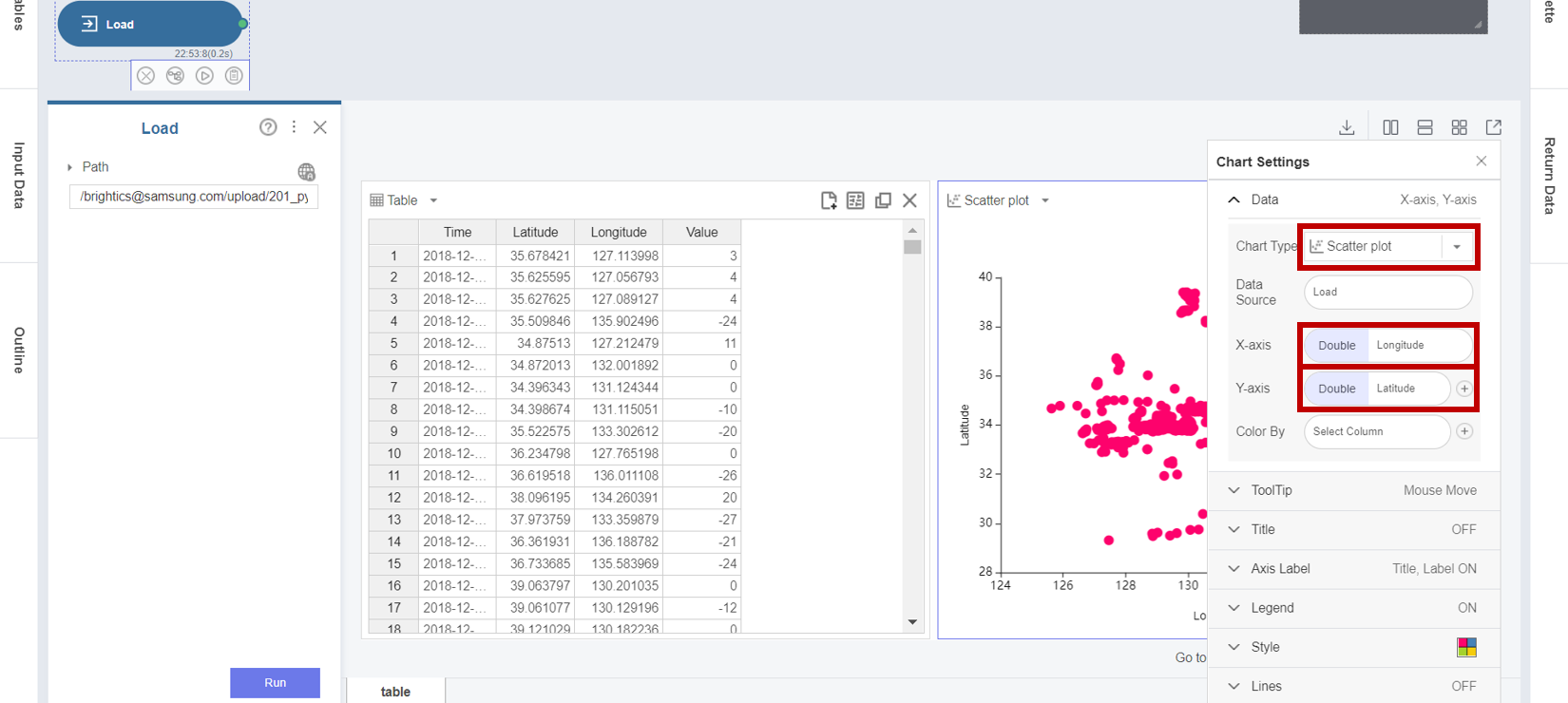
1. Load 함수의 경로를 업로드한 데이터인 11_py_outlier_detection 로 지정하여 실행한 후 Chart Settings 버튼을 클릭합니다.
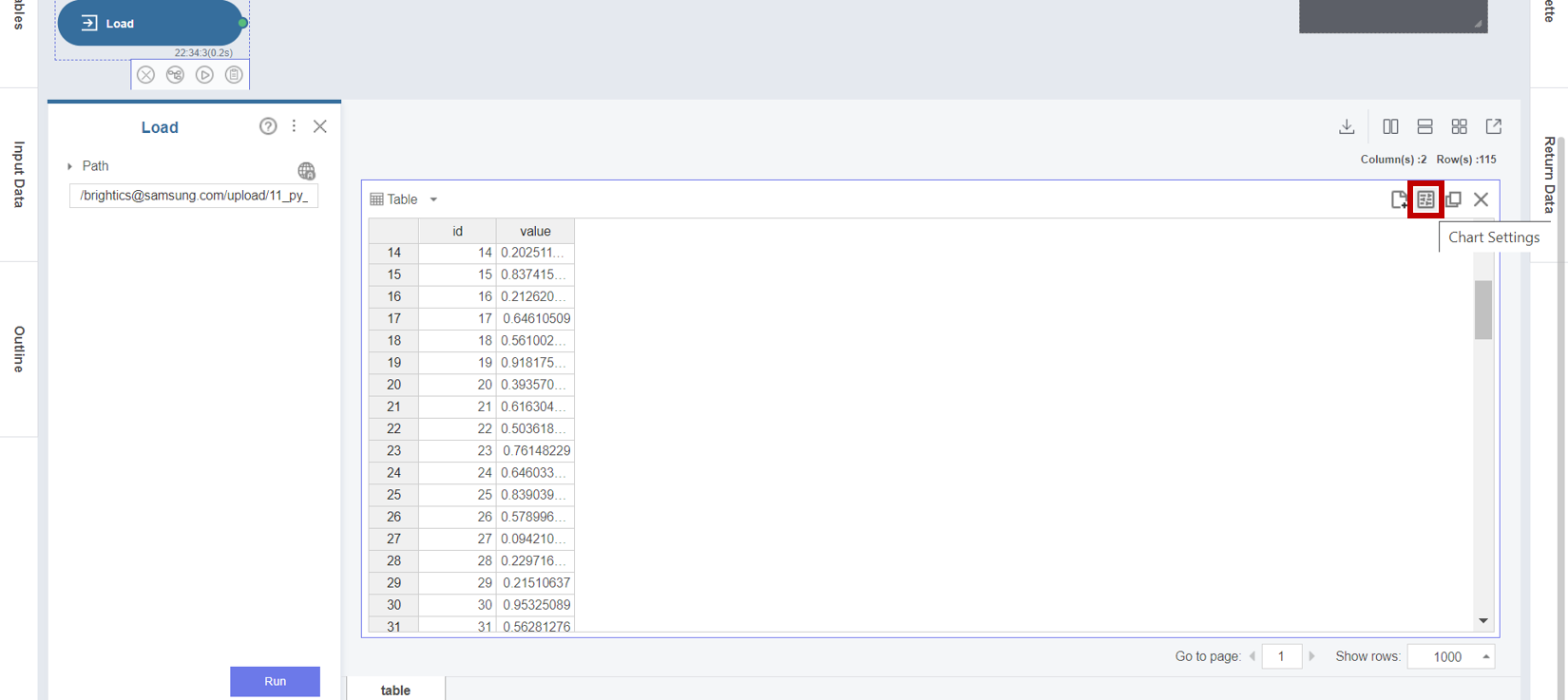
2. Chart Settings에서 데이터의 분포를 시각화하기 위해 Chart Type을 Box plot으로 선택하고,
X-axis를 Column Names로, Y-axis를 value로 설정합니다.
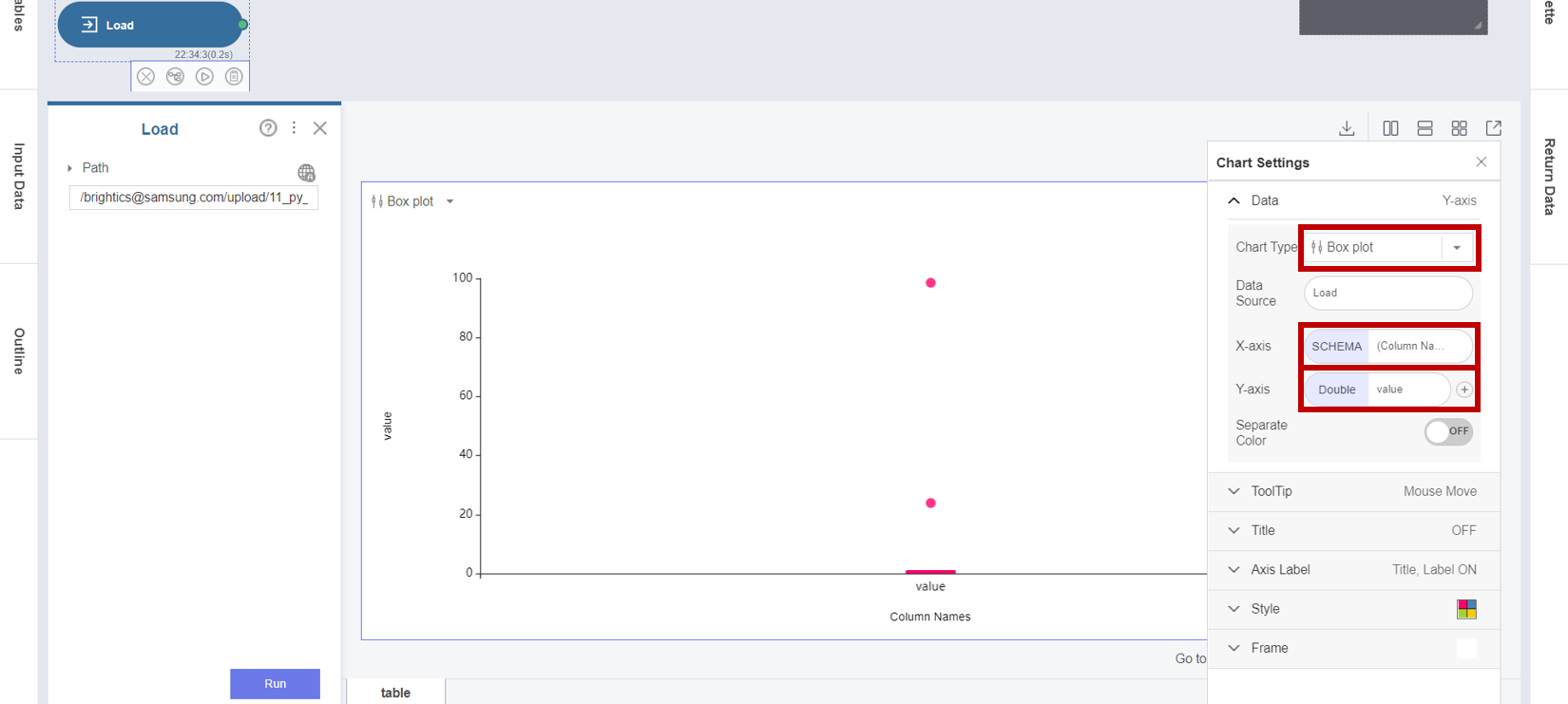
3. Load 함수의 Box Plot 차트의 결과를 통해 2개의 데이터 포인트가 나머지 데이터 분포로부터 매우 멀리 떨어져 있는 이상값임을 확인할 수 있습니다.
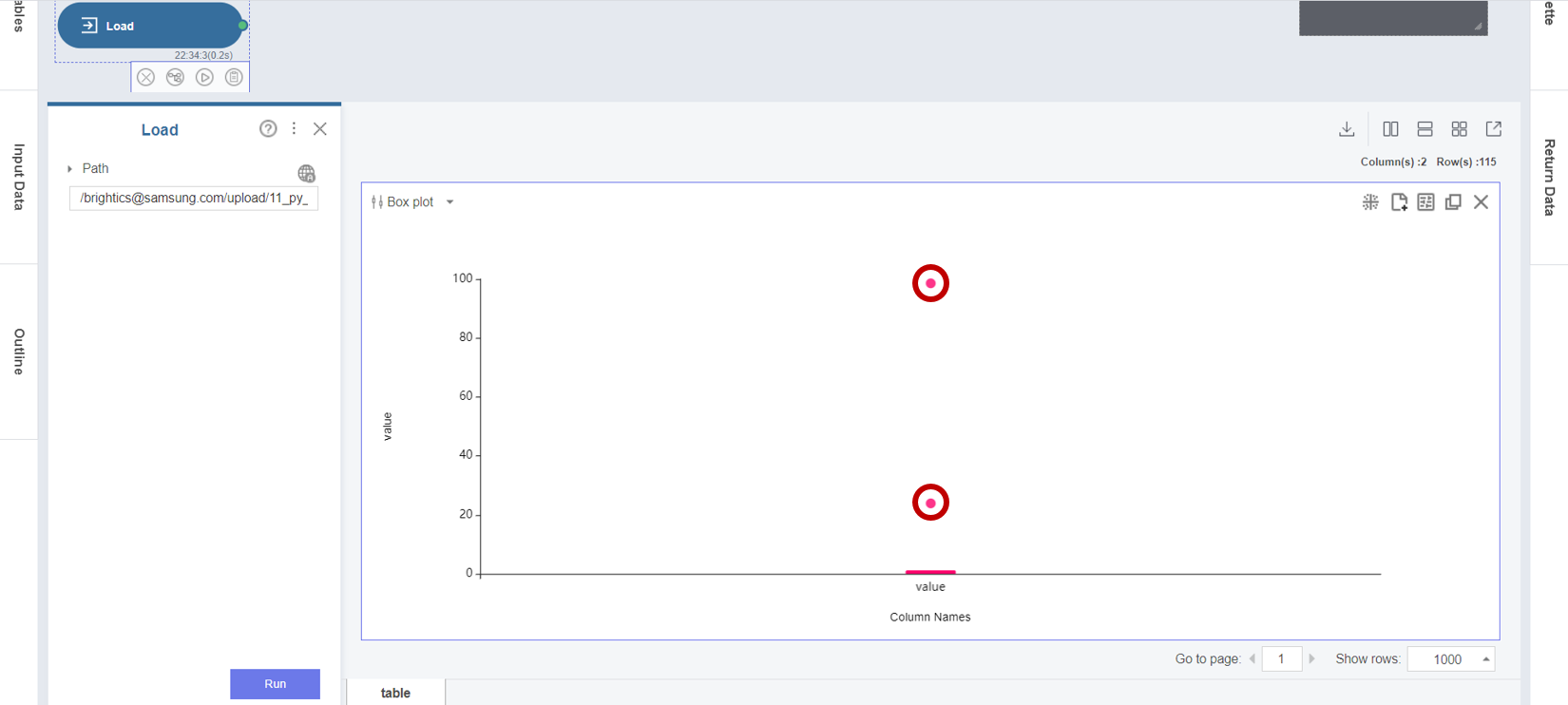
■ Modeling ( Outlier Detection (Tukey/Carling) 함수 )
▶▷ Outlier Detection 함수를 이용하여 Outlier을 제거하고 데이터의 분포를 Box Plot으로 확인하기 ◁◀
1. 새로운 함수를 생성하기 위해서 Select Fuction 팝업창이 뜨면, Outlier Detection (Tukey/Carling) 함수 버튼을 클릭합니다.
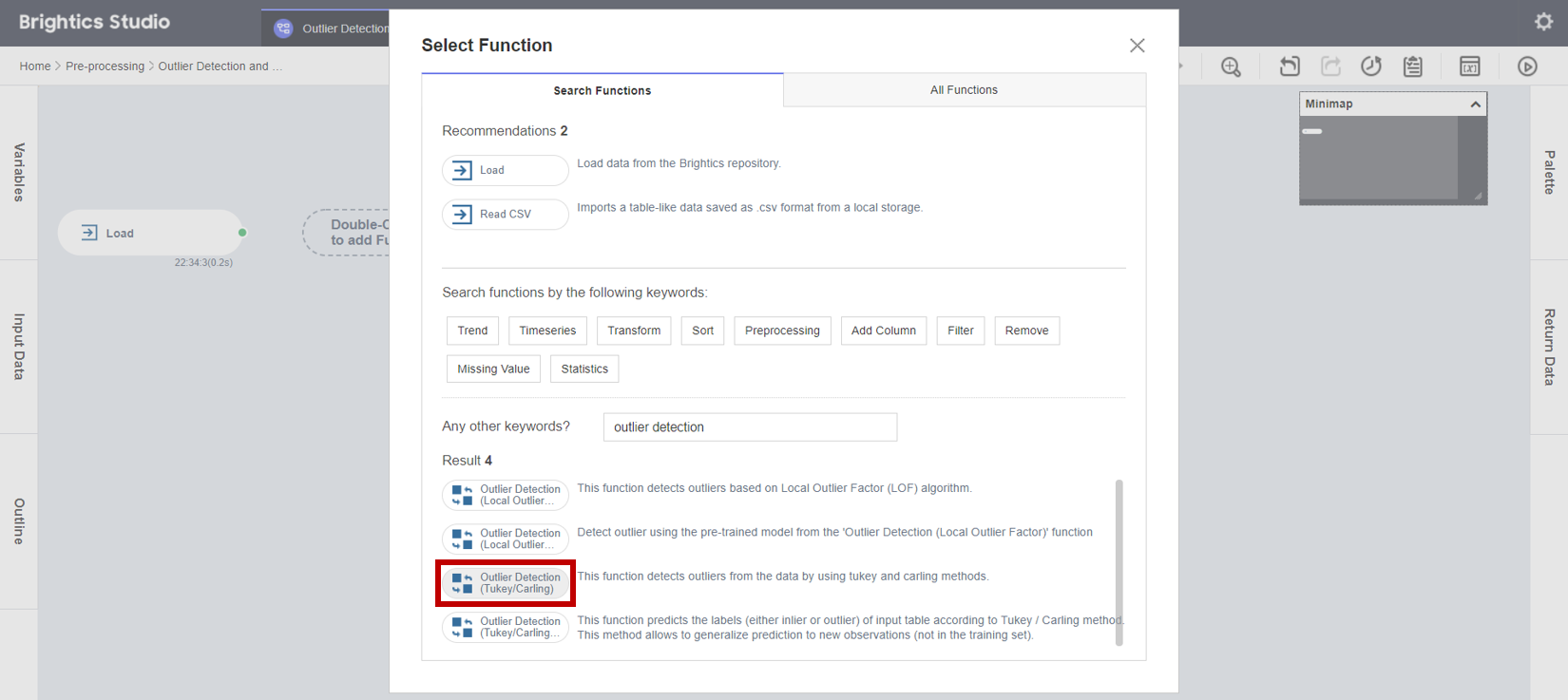
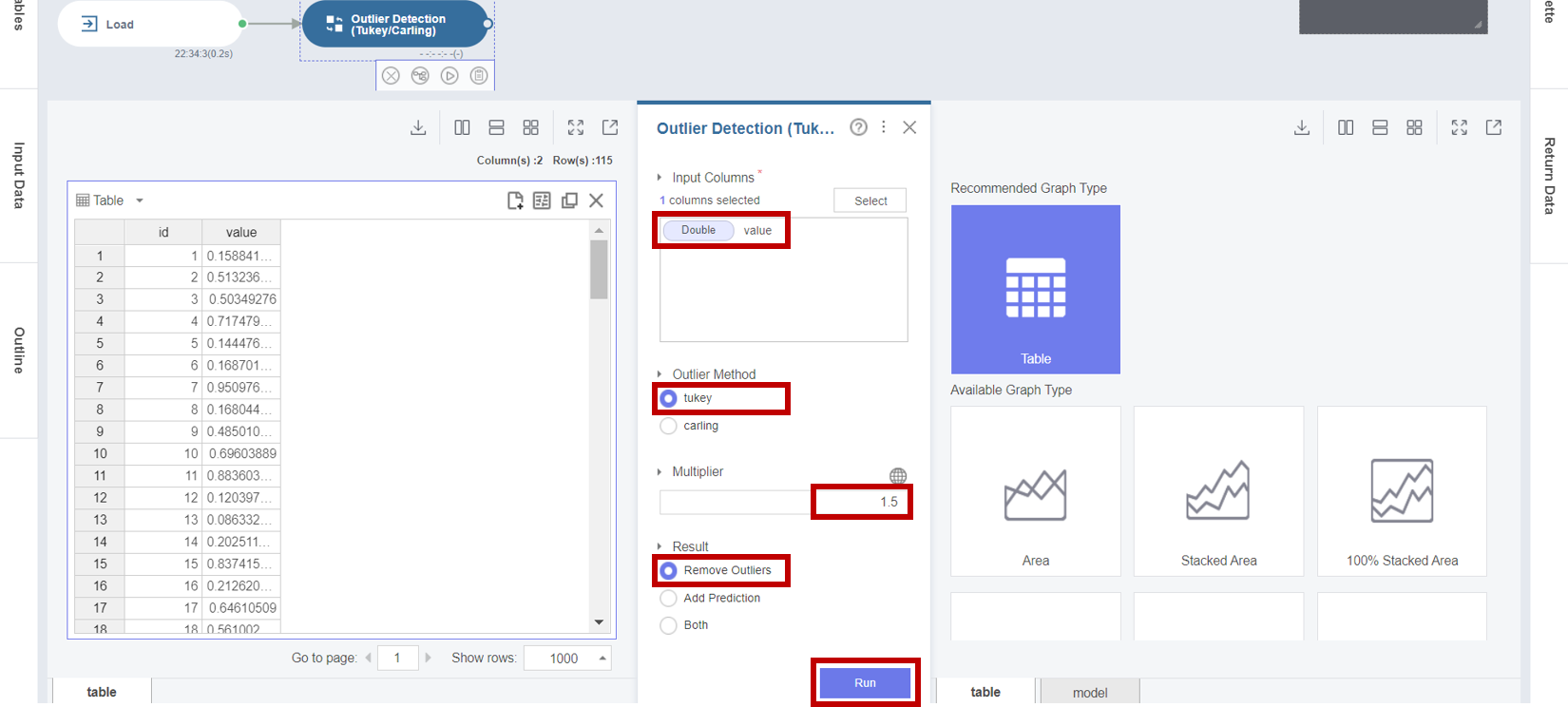
2. Outlier Detection (Tukey/Carling) 함수에서 Tukey 방법을 이용하여 value 컬럼의 이상값을 제거하기 위해
Input Columns로 value를 선택하고, Outlier Method로 tukey를 선택하고, Multiplier로 1.5를 입력하고 Result로 Remove Outliers를 선택한 후 Run 버튼을 클릭합니다.
3. Outlier Detection (Tukey/Carling) 함수의 실행 결과 데이터 분포를 시각화하기 위해 Chart Settings를 클릭합니다.
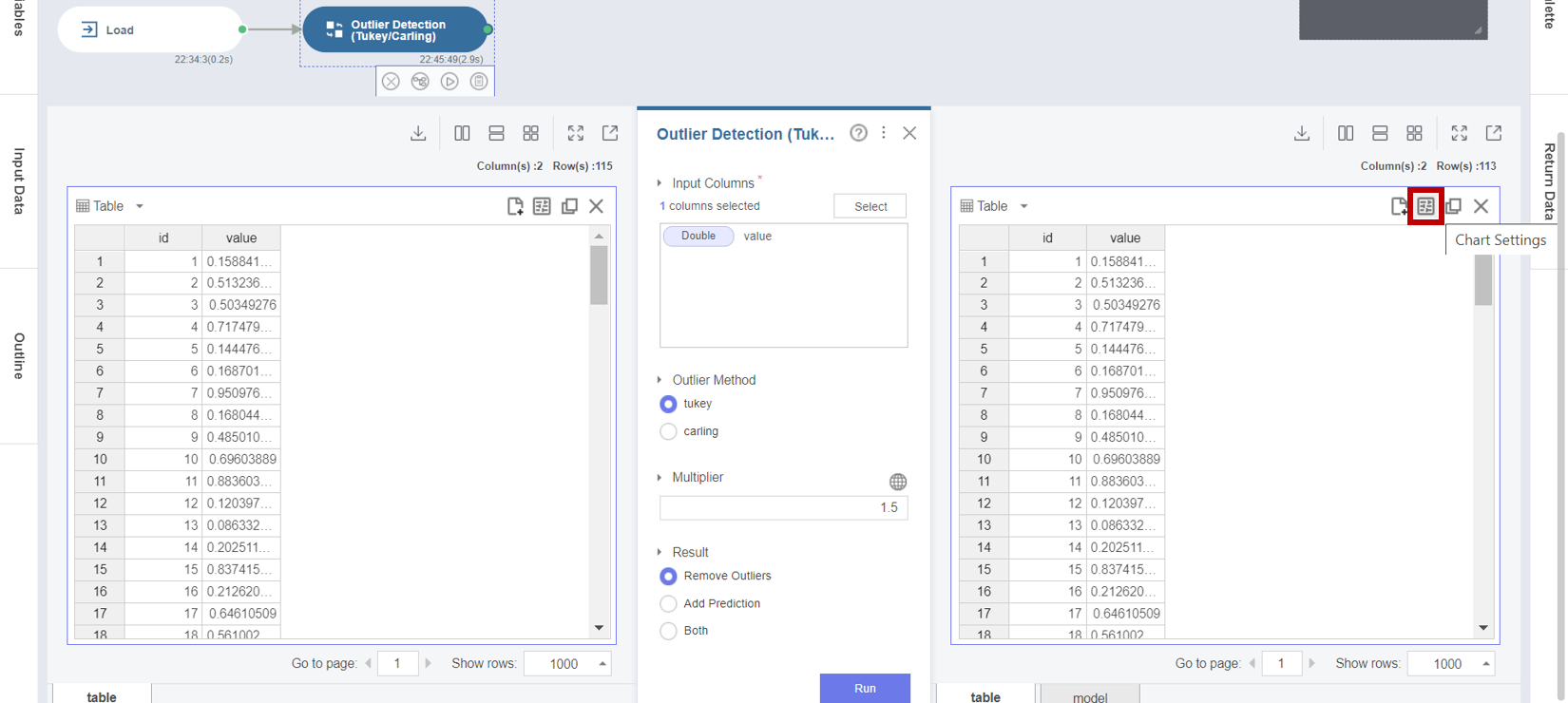
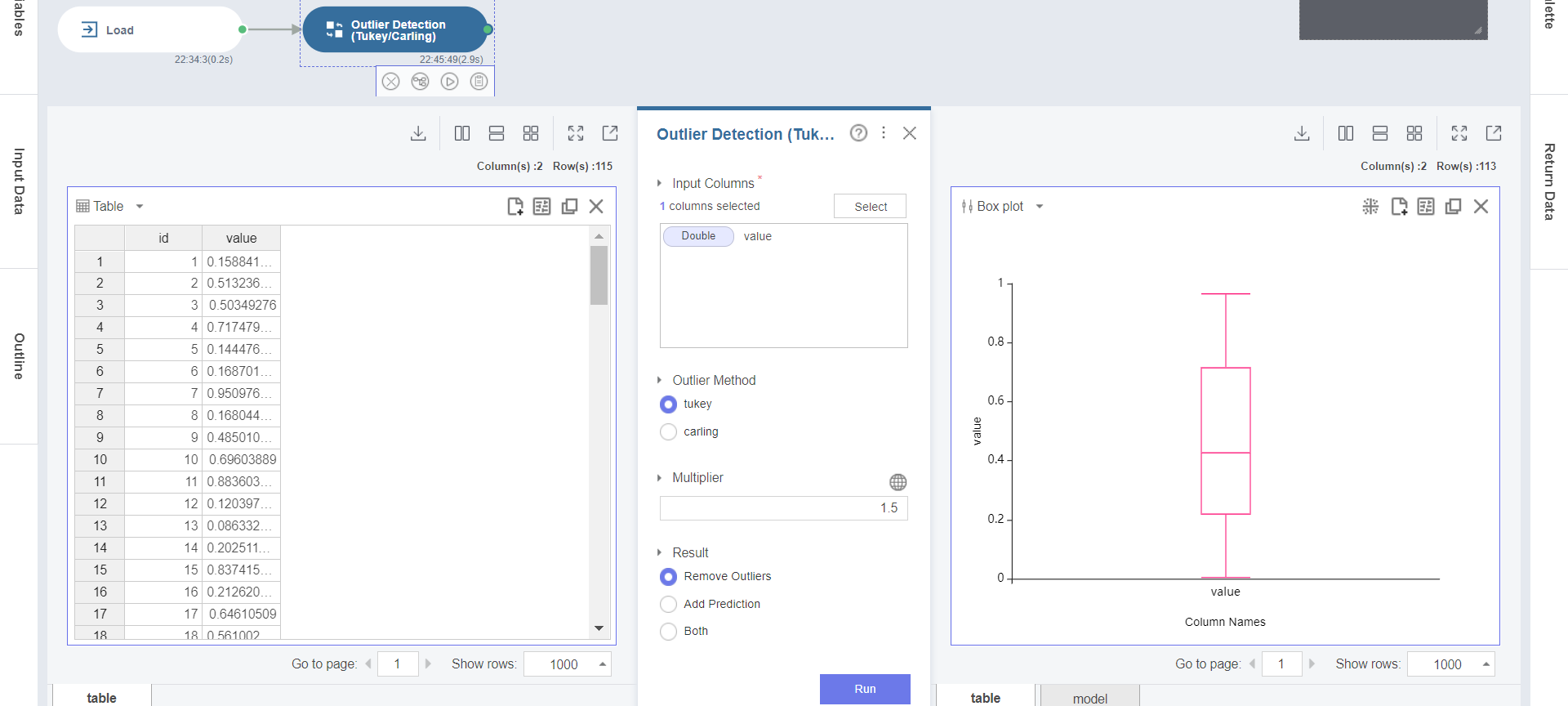
4. Chart Settings에서 Chart Type을 Box plot로 선택하고, X-axis를 Column Names로, Y-axis를 value로 설정합니다.
5. Outlier Detection (Tukey/Carling) 함수의 Box Plot 차트의 결과를 통해 2개의 이상값이 제거되어 데이터의 분포가 달라진 것을 확인할 수 있습니다.
지금까지 ~ 전처리 - 이상값 탐지 및 제거(1) Tukey 방법 활용 튜토리얼 실습이었습니다 !
※ Tutorial → [ Pre-processing ] Outlier Detection and Removal (1)
감사합니다 :)
https://www.brightics.ai/kr/docs/ai/s1.0/tutorials/11_py_outlier_detection?type=insight
Brightics Studio
www.brightics.ai
'Samsung SDS Brightics' 카테고리의 다른 글
| [Samsung SDS Brightics] EDA : 모집단이 여러개일 때 평균 비교 분석하기 → ANOVA와 사후검정 (0) | 2020.08.11 |
|---|---|
| [Samsung SDS Brightics] Pre-processing : 이상값 탐지 및 제거 (2) (0) | 2020.08.04 |
| [Samsung SDS Brightics] Pre-processing : 결측값 처리 (2) (0) | 2020.08.02 |
| [Samsung SDS Brightics] Pre-processing : 결측값 처리 (1) (0) | 2020.08.01 |
| [Samsung SDS Brightics] Pre-processing : 데이터 샘플링 (0) | 2020.07.28 |
- Total
- Today
- Yesterday
- Wifi Free
- Outlier Detection and Removal
- Brightics vs R
- ANOVA 검정
- 이상값
- 브라이틱스
- 한국공항공사
- 전파누리
- 삼성 SDS 데이터 분석
- Pre-processing
- 데이터 전처리
- 브라이틱스 스튜디오
- 데이터참쉽조
- 데이터전처리
- Brightics Studio
- mtcars
- 결측값 처리
- Brightics 개인미션
- 삼성 SDS
- Brightics 팀미션
- Brightics AI
- Public Wifi
- Brightics 홍보 UCC
- 전처리 과정
- Brightics Studio 실습
- Brightics Tutorial
- 브라이틱스 튜토리얼
- Brightics 분석 프로젝트
- 전처리
- 이상값 탐지 및 제거
- Brightics 개인 분석 프로젝트
- eda
- ANOVA
- 결측치 처리
- 분석 프로젝트
- Brightics 팀 분석 프로젝트
- Brightics 서포터즈
- data analysis
- Missing Value
- 삼성 SDS 데이터 분석 프로젝트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |